
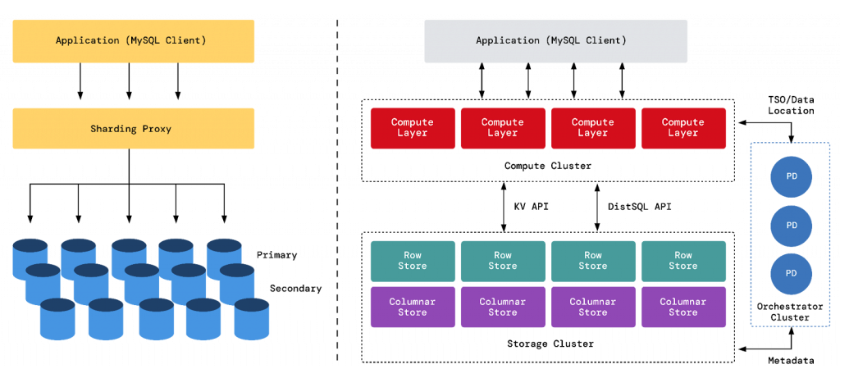


📘 1. Introduction to Distributed Databases
A Distributed Database is a collection of multiple interconnected databases spread across different physical locations but functioning as a single logical database system. These locations may include:
- Different servers
- Data centers
- Geographic regions
- Cloud environments
The key idea is:
👉 Data is distributed, but access is unified.
🔹 Definition
A distributed database system (DDBS) consists of:
- Multiple databases located on different machines
- A network connecting them
- Software that manages distribution and transparency
🔹 Key Characteristics
- Data stored across multiple nodes
- Appears as a single database to users
- Supports distributed processing
- Enables high availability and scalability
🧠 2. Why Distributed Databases Are Needed
🔹 Limitations of Centralized Databases
- Single point of failure
- Limited scalability
- High latency for distant users
- Resource bottlenecks
🔹 Benefits of Distribution
- Faster access (data closer to users)
- Fault tolerance
- Load balancing
- Scalability
🔹 Real-World Examples
- Banking systems
- Social media platforms
- E-commerce systems
- Cloud-based applications
🏗️ 3. Architecture of Distributed Databases
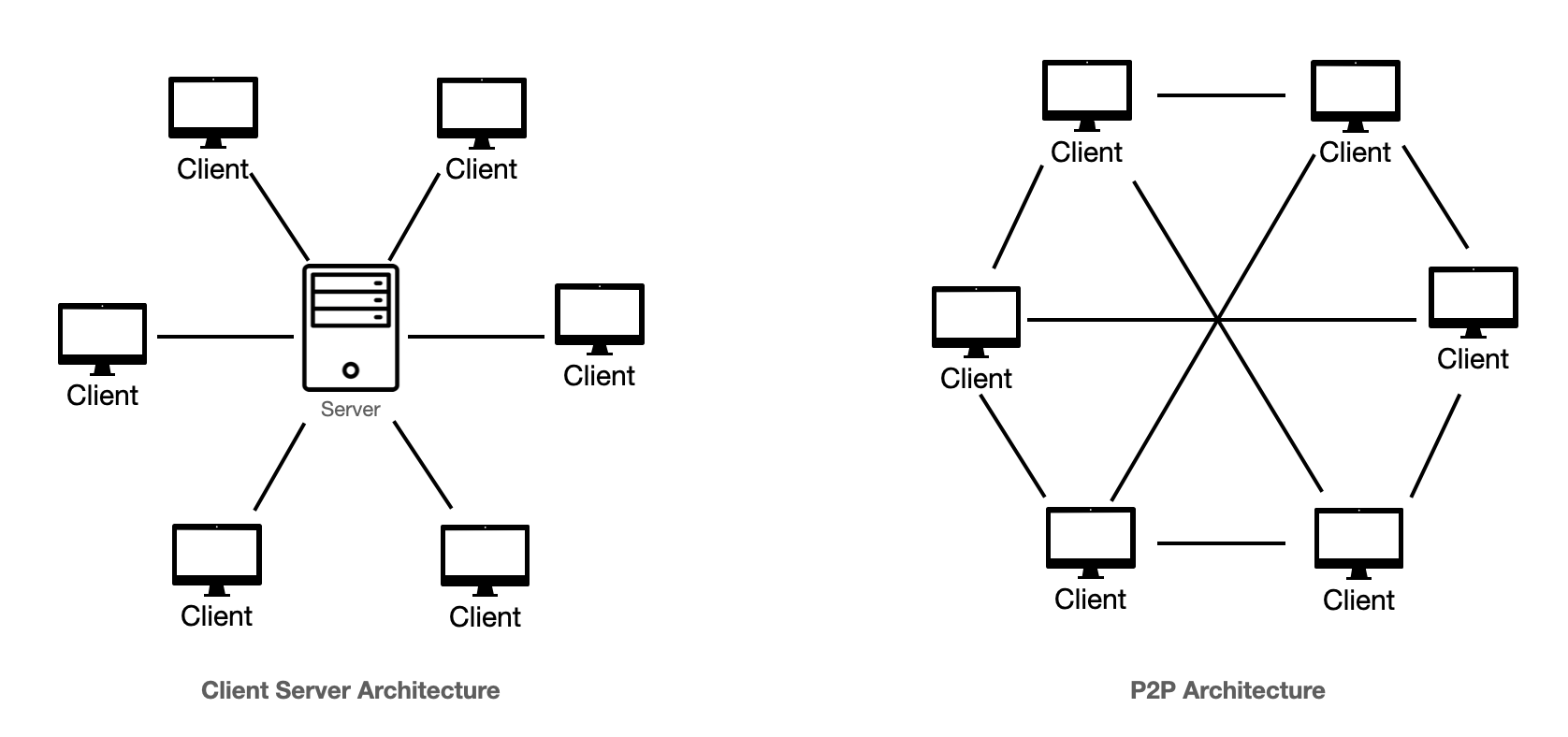



🔹 Types of Architecture
1. Client-Server Architecture
- Clients request data
- Servers process queries
2. Peer-to-Peer Architecture
- All nodes are equal
- Each node can act as client and server
3. Multi-tier Architecture
- Presentation layer
- Application layer
- Database layer
🔹 Shared-Nothing Architecture
- Each node has its own memory and storage
- No shared resources
- Highly scalable
🧩 4. Types of Distributed Databases
🔹 1. Homogeneous Distributed Database
- Same DBMS across all nodes
- Easier to manage
🔹 2. Heterogeneous Distributed Database
- Different DBMS systems
- Complex integration
🔹 3. Federated Databases
- Independent databases connected logically
- Maintain autonomy
🔄 5. Data Distribution Techniques

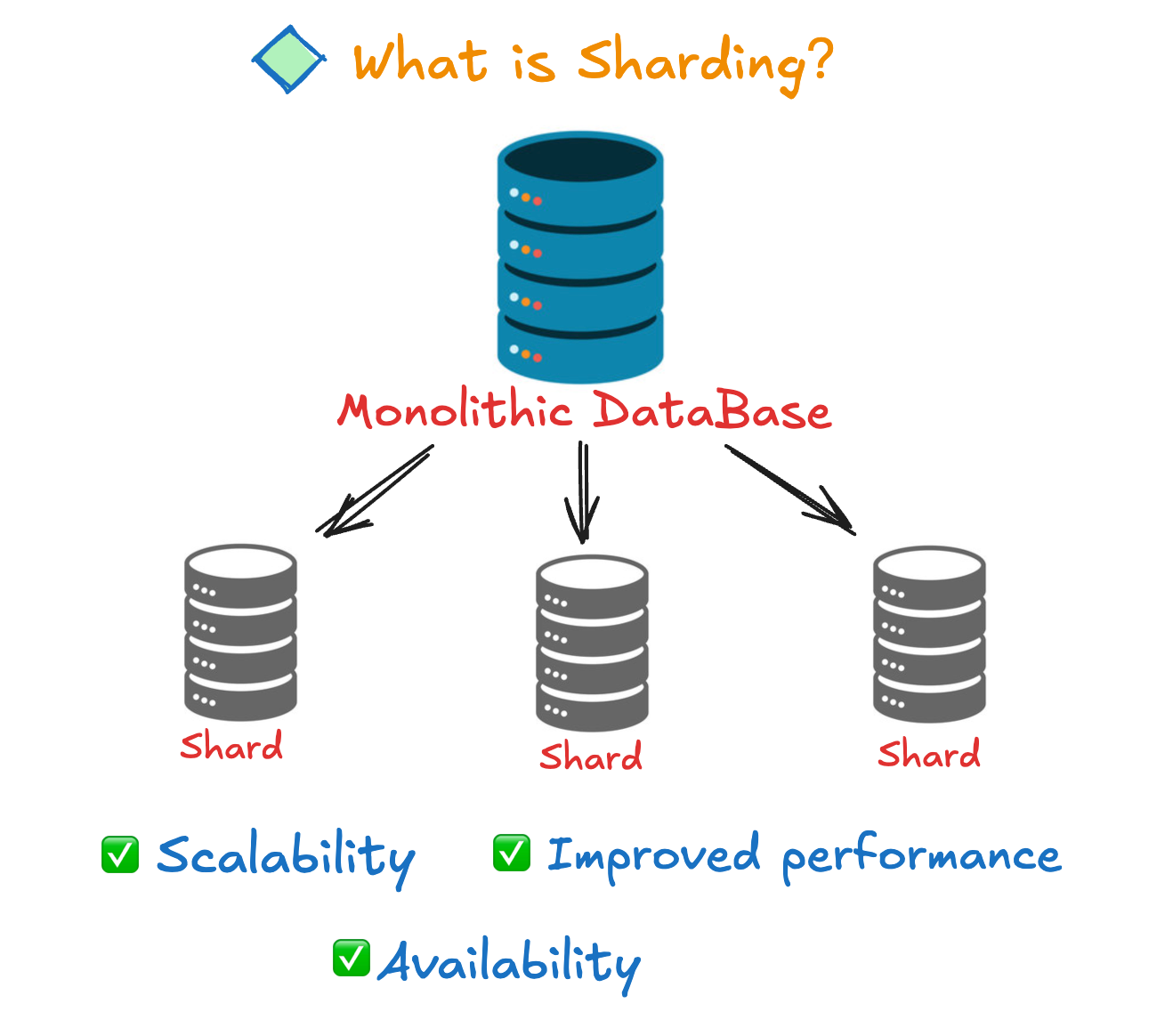

🔹 1. Fragmentation
Types:
- Horizontal Fragmentation → rows distributed
- Vertical Fragmentation → columns distributed
- Hybrid Fragmentation → combination
🔹 2. Replication
- Copies data across multiple nodes
Types:
- Full replication
- Partial replication
🔹 3. Sharding
- Splitting data into smaller chunks (shards)
🔐 6. Transparency in Distributed Databases
🔹 Types of Transparency
- Location transparency
- Replication transparency
- Fragmentation transparency
- Naming transparency
👉 Users do not need to know where data is stored.
⚖️ 7. CAP Theorem



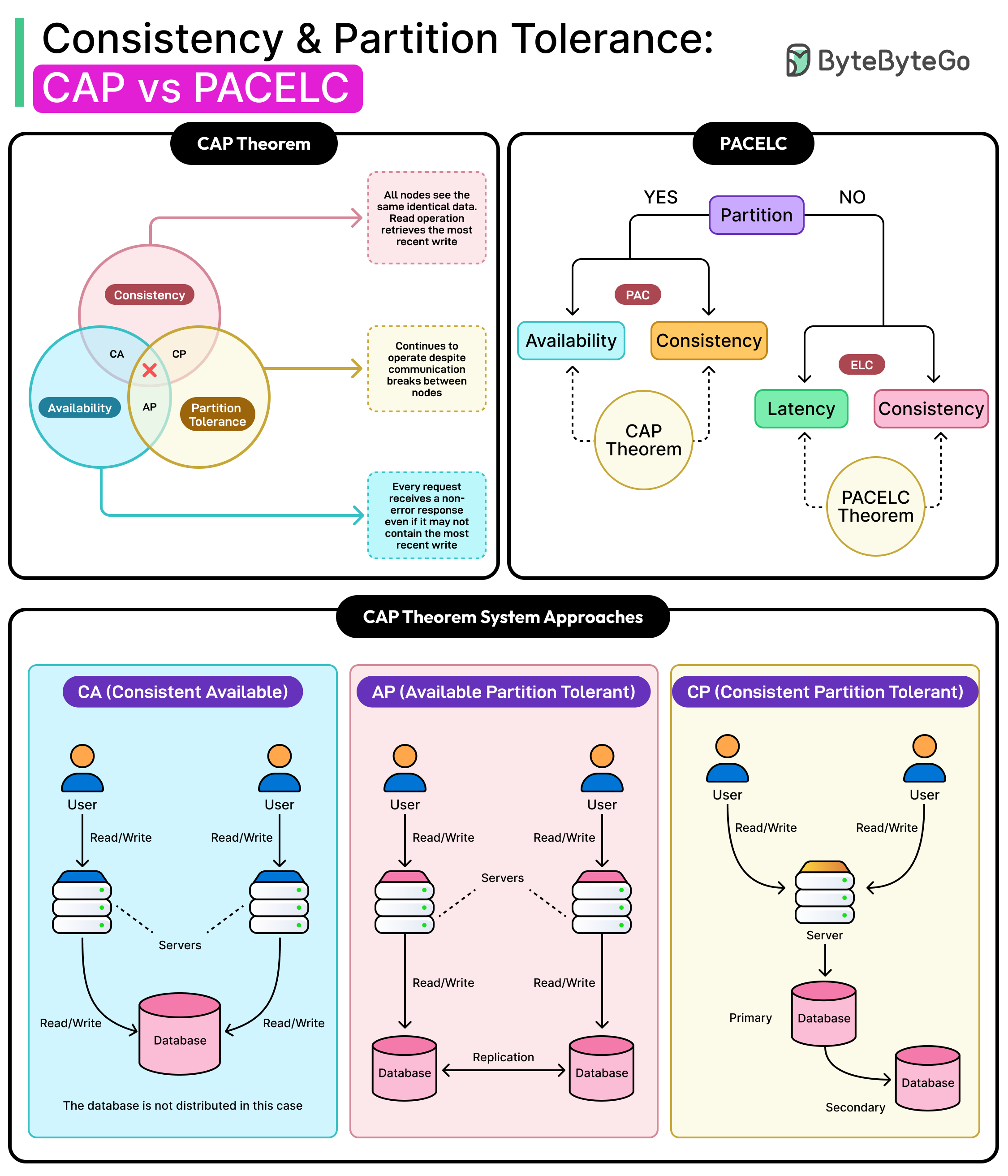
CAP theorem states that a distributed system can provide only two of:
- Consistency
- Availability
- Partition tolerance
🔹 Trade-offs
- CP systems → strong consistency
- AP systems → high availability
🔄 8. Distributed Transactions


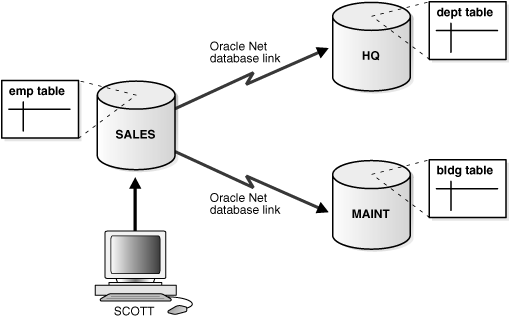
🔹 Challenges
- Maintaining consistency across nodes
- Handling failures
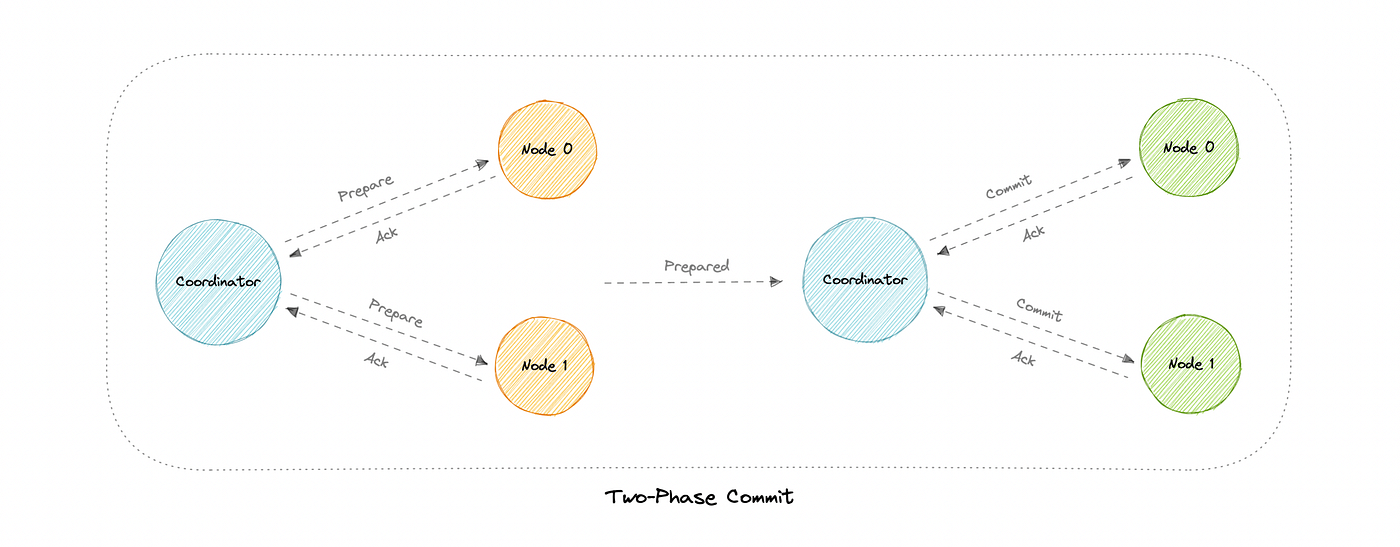
🔹 Two-Phase Commit (2PC)
Phase 1: Prepare
- Nodes prepare to commit
Phase 2: Commit
- All nodes commit or rollback
🔹 Three-Phase Commit (3PC)
- Adds extra phase
- Reduces blocking
🧠 9. Concurrency Control
🔹 Techniques
- Distributed locking
- Timestamp ordering
- Optimistic concurrency
🔹 Challenges
- Synchronization
- Deadlocks
🔁 10. Data Consistency Models
🔹 Types
- Strong consistency
- Eventual consistency
- Causal consistency
🔐 11. Fault Tolerance
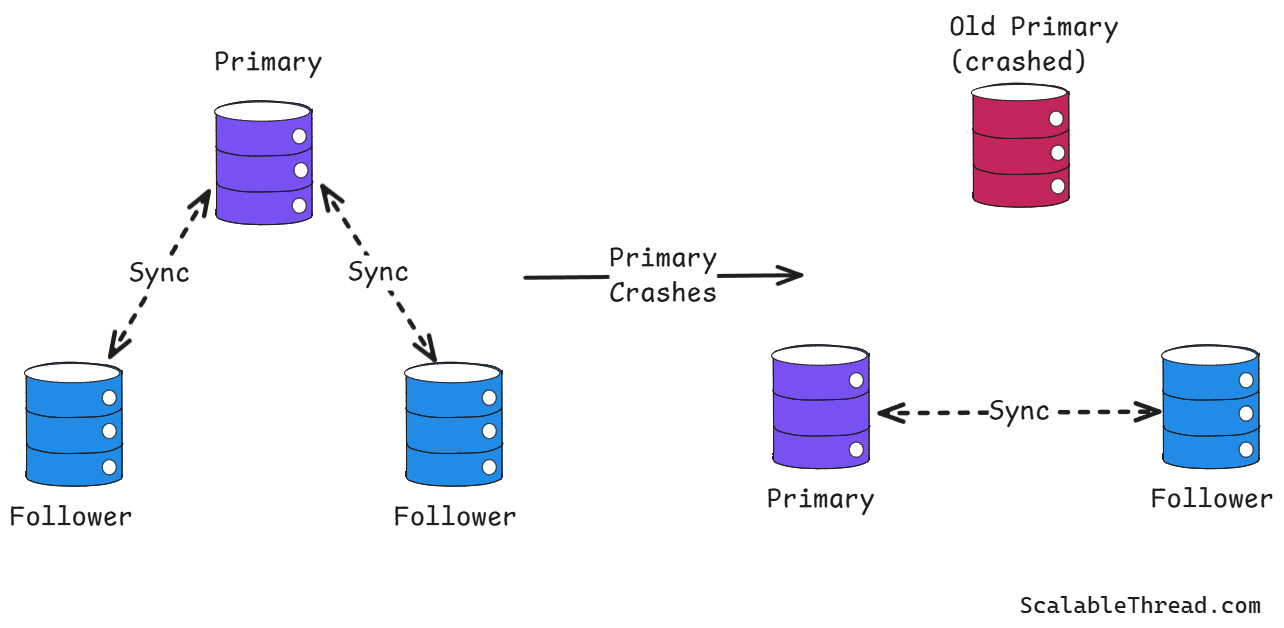

🔹 Techniques
- Replication
- Failover mechanisms
- Backup systems
⚡ 12. Performance Optimization
🔹 Techniques
- Load balancing
- Data locality
- Query optimization
🌐 13. Distributed Query Processing
🔹 Steps
- Query decomposition
- Data localization
- Optimization
- Execution
🧩 14. Distributed Database Design
🔹 Design Considerations
- Data distribution strategy
- Network latency
- Scalability
🧪 15. Security in Distributed Databases
🔹 Measures
- Encryption
- Authentication
- Access control
📊 16. Real-World Applications
🔹 Banking Systems
- Global transactions
🔹 Social Media
- User data distribution
🔹 E-commerce
- Global product catalogs
🔹 Cloud Services
- Distributed storage
⚖️ 17. Advantages of Distributed Databases
- High availability
- Scalability
- Fault tolerance
- Performance
⚠️ 18. Disadvantages
- Complexity
- Security challenges
- Data inconsistency risks
🧠 19. Distributed vs Centralized Databases
| Feature | Centralized | Distributed |
|---|---|---|
| Data Location | Single | Multiple |
| Scalability | Limited | High |
| Fault Tolerance | Low | High |
🔄 20. Emerging Trends
- Cloud-native distributed databases
- Serverless databases
- Edge computing
🏁 Conclusion
Distributed databases are the backbone of modern scalable systems. They enable organizations to handle massive data, global users, and high availability requirements.
While they introduce complexity, their benefits in scalability and performance make them essential for today’s applications.