Introduction to Regression and Correlation
In statistics and mathematics, understanding relationships between variables is an essential part of data analysis. Two important statistical tools used to study these relationships are correlation and regression. These techniques help researchers determine whether variables are related and how one variable may influence another.
Correlation measures the strength and direction of a relationship between two variables, while regression is used to model the relationship and predict values of one variable based on another.
For example:
- A researcher may study the relationship between hours studied and exam scores.
- Economists may analyze the relationship between income and spending.
- Businesses may analyze advertising expenditure and sales revenue.
In all these situations, correlation and regression help identify patterns and relationships within data.
These concepts are widely used in fields such as economics, engineering, finance, social sciences, medicine, and machine learning. They provide valuable insights into how variables interact and how changes in one variable affect another.
Understanding regression and correlation allows statisticians to interpret data more effectively and develop predictive models.
Understanding Correlation



Definition of Correlation
Correlation refers to the statistical relationship between two variables. It measures how strongly and in what direction the variables are related.
When two variables change together, they are said to be correlated.
Examples:
- As temperature increases, ice cream sales increase.
- As hours studied increase, exam scores tend to increase.
- As price increases, demand may decrease.
Correlation helps determine whether there is a linear relationship between variables.
However, correlation does not imply causation. Two variables may be correlated without one causing the other.
Types of Correlation

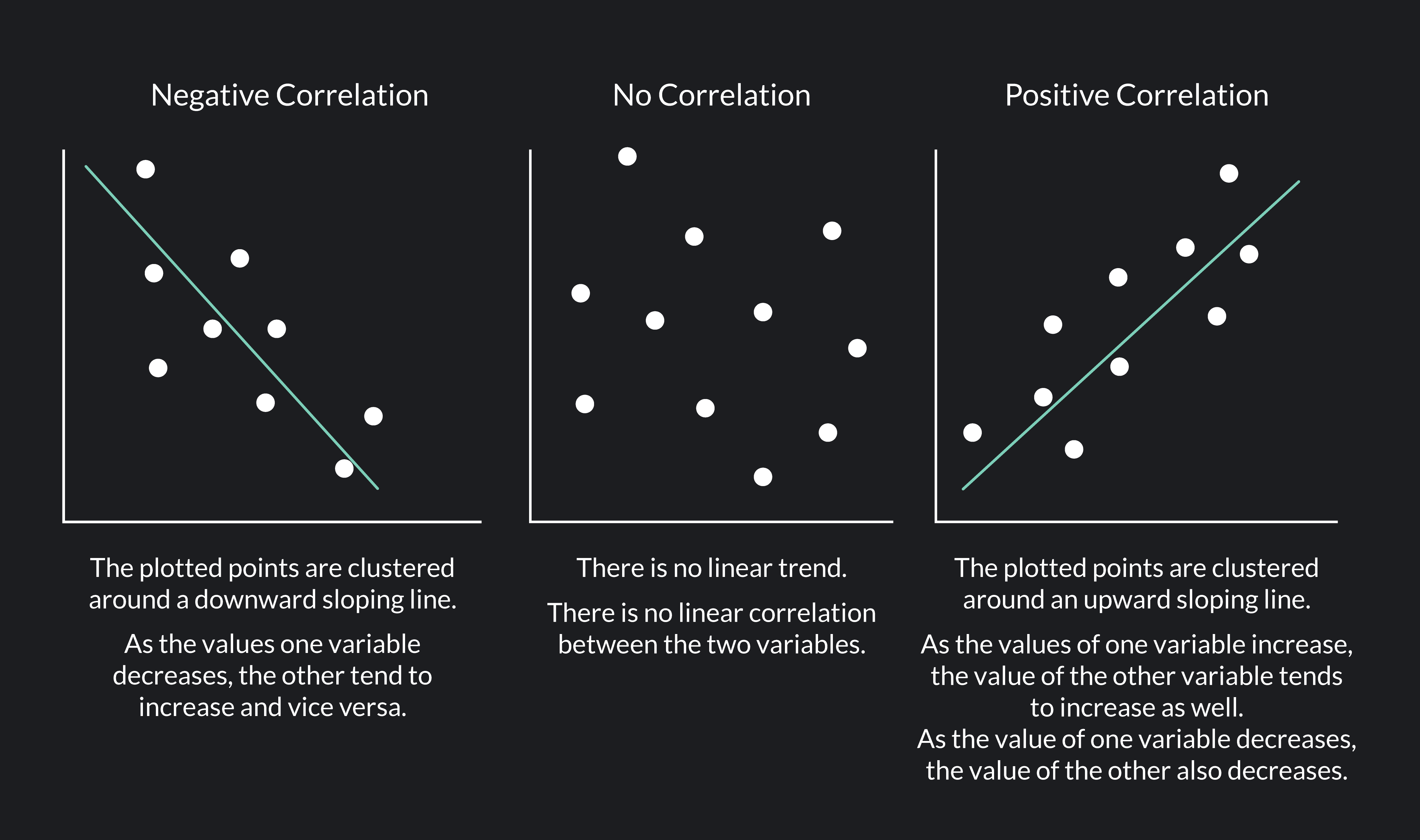
There are three main types of correlation.
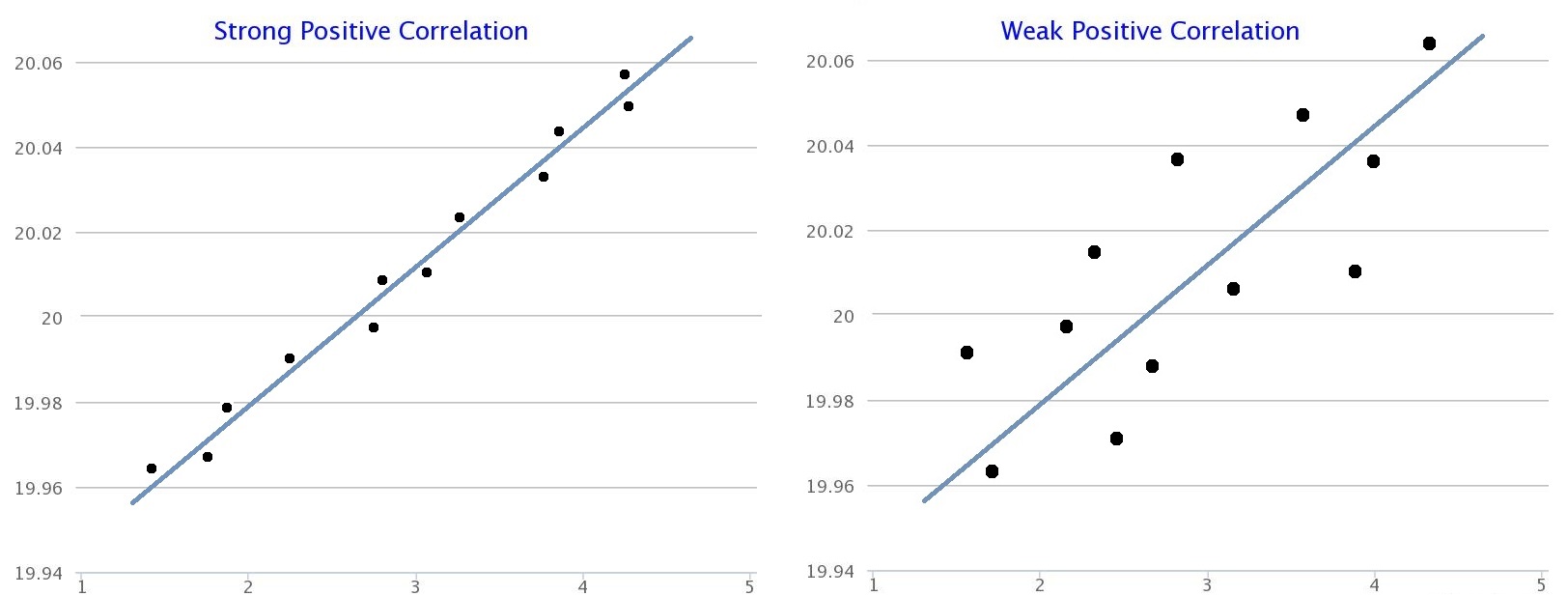
Positive Correlation
Positive correlation occurs when both variables increase together.
Example:
- More hours studied → higher exam scores
In scatter plots, the data points trend upward.
Negative Correlation
Negative correlation occurs when one variable increases while the other decreases.
Example:
- Higher prices → lower demand
In scatter plots, the data points trend downward.
Zero Correlation
Zero correlation occurs when there is no relationship between the variables.
Example:
- Shoe size and intelligence.
In scatter plots, the points appear randomly distributed.
Correlation Coefficient



The strength of correlation is measured using the correlation coefficient, usually denoted by r.
The correlation coefficient ranges between −1 and +1.
Values of r indicate the following:
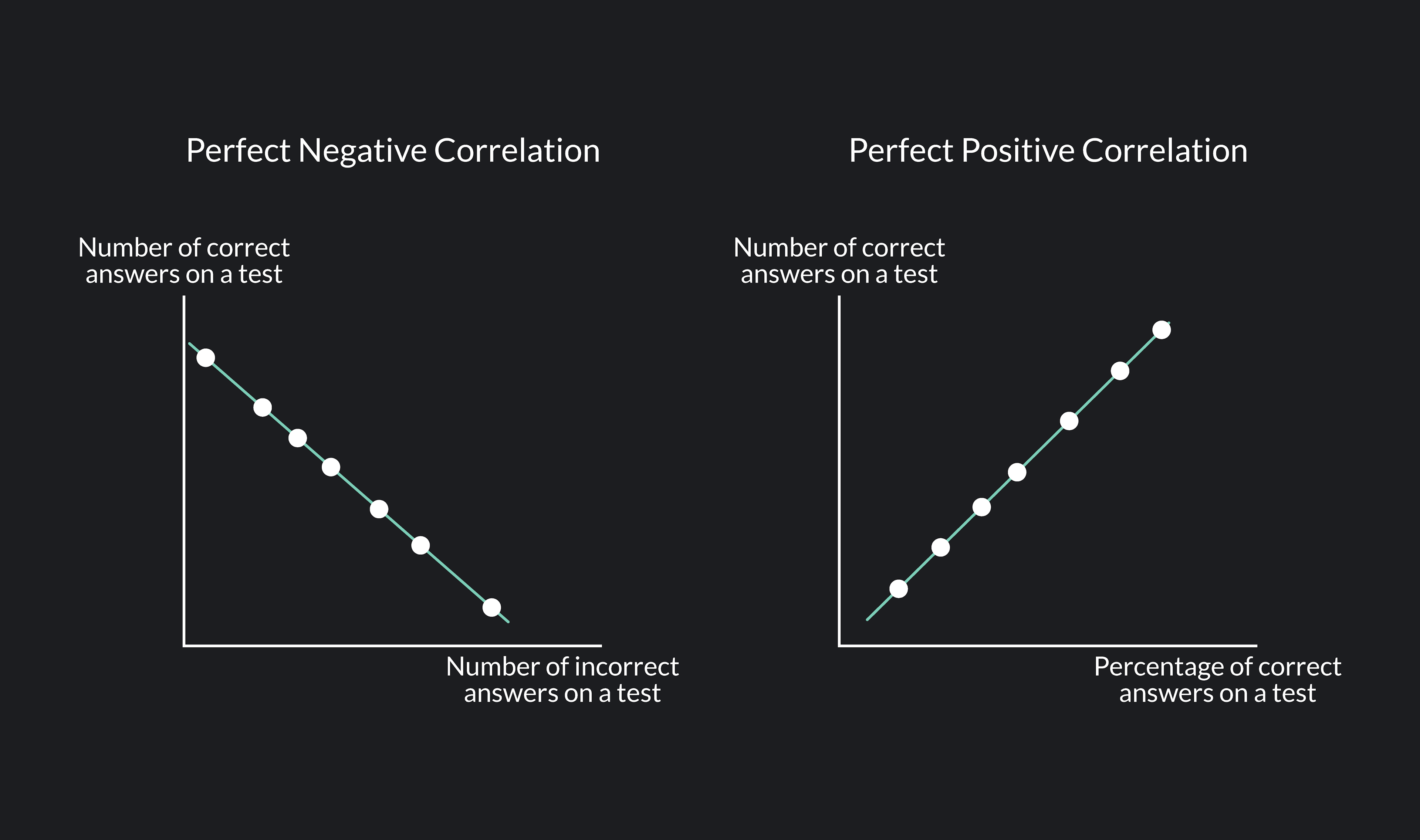
- r = +1 → perfect positive correlation
- r = −1 → perfect negative correlation
- r = 0 → no correlation
Values closer to +1 or −1 indicate stronger relationships.
Pearson Correlation Coefficient
The Pearson correlation coefficient is calculated using the formula:
r = Σ[(x − x̄)(y − ȳ)] / √[Σ(x − x̄)² Σ(y − ȳ)²]
Where:
- x and y represent variables
- x̄ and ȳ represent means
This formula measures the linear relationship between two variables.
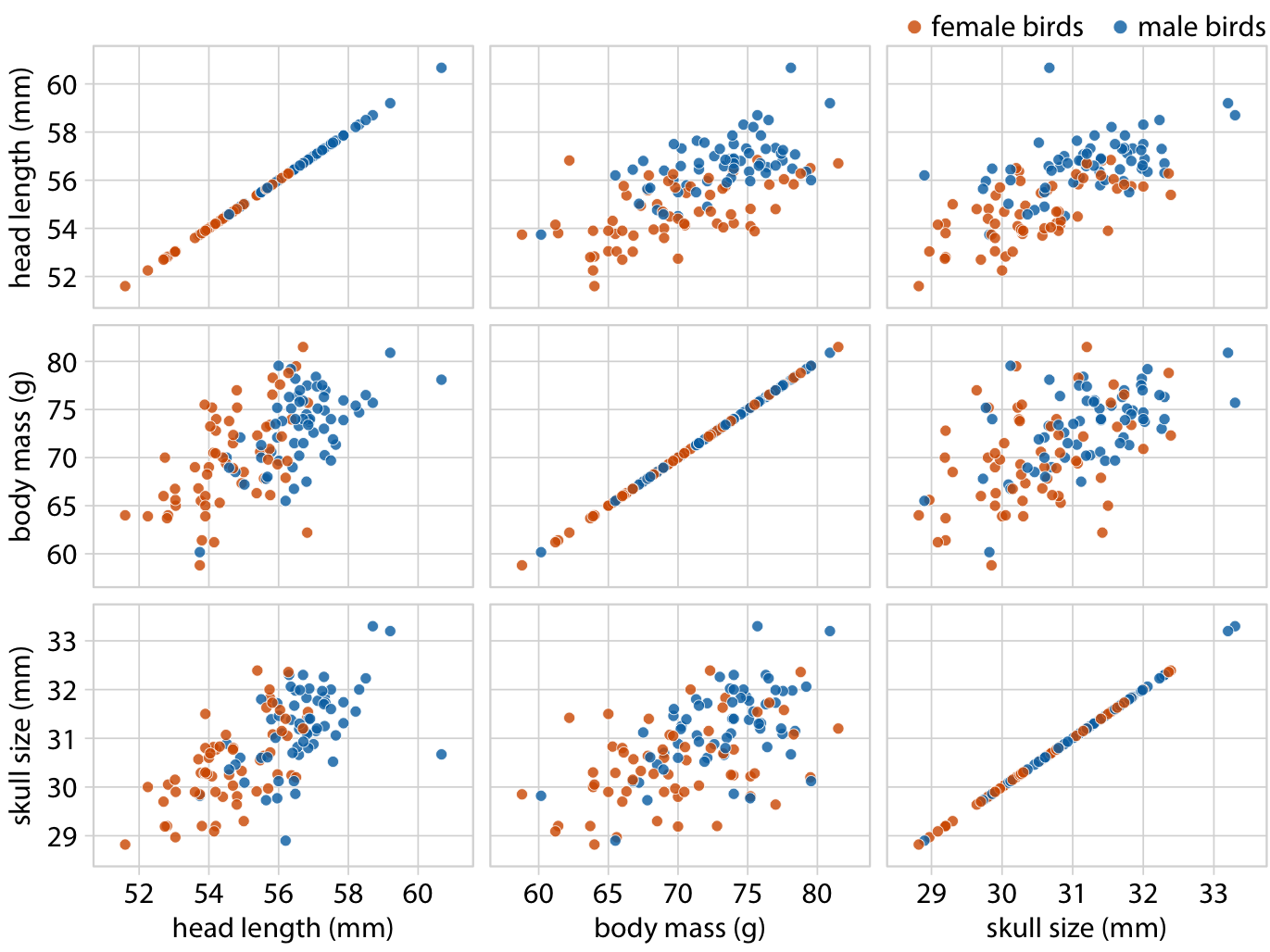
Scatter Diagrams



A scatter diagram is a graphical representation used to visualize the relationship between two variables.
In a scatter plot:
- One variable is plotted on the x-axis.
- The other variable is plotted on the y-axis.
Each point represents a pair of values.
Scatter diagrams help identify:
- direction of correlation
- strength of correlation
- presence of outliers
They are often the first step in regression analysis.
Understanding Regression


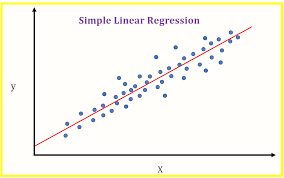

Regression analysis is used to describe the relationship between variables and make predictions.
While correlation measures the strength of the relationship, regression determines the mathematical equation describing the relationship.
For example:
If a relationship exists between study hours and exam scores, regression can be used to predict exam scores based on study hours.
Regression analysis identifies the best-fit line that represents the relationship between variables.
Linear Regression
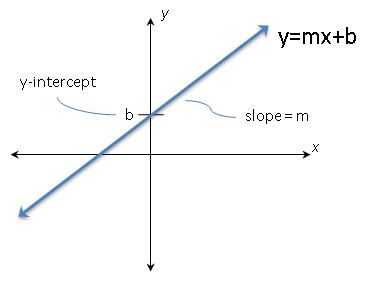

The most common form of regression is linear regression.
The linear regression equation is:
y = a + bx
Where:
- y = dependent variable
- x = independent variable
- a = intercept
- b = slope of the line
The slope represents how much y changes when x increases by one unit.
Regression uses the least squares method to determine the best-fitting line.
Multiple Regression

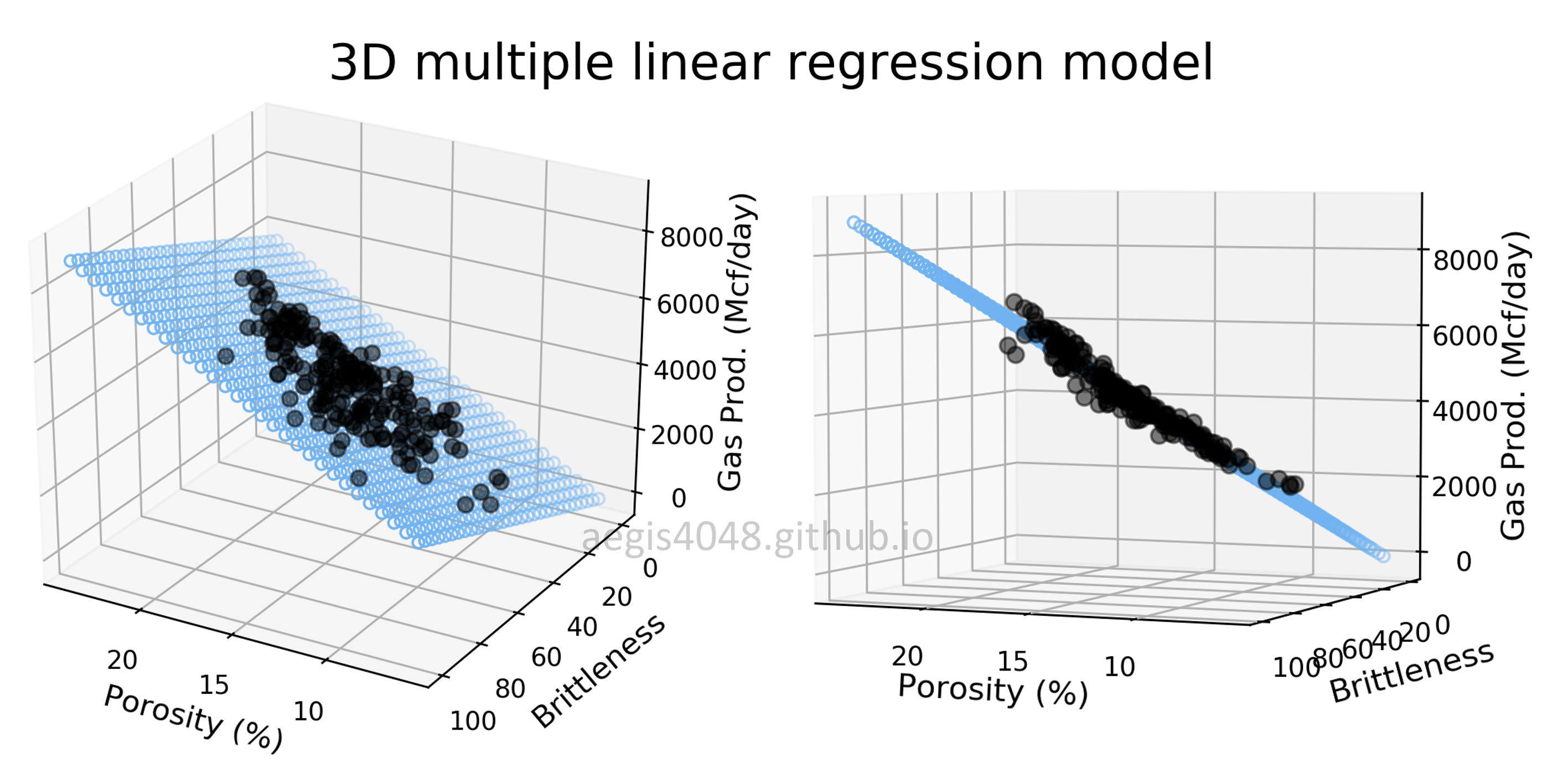

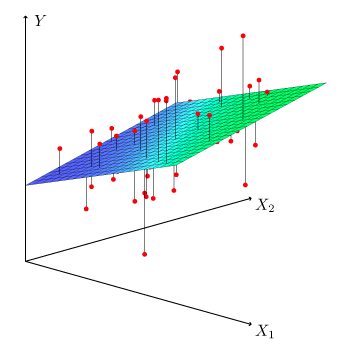
In many situations, a dependent variable depends on several independent variables.
Multiple regression models these relationships.
Example:
House price may depend on:
- size of the house
- location
- number of bedrooms
- age of the building
The multiple regression equation is:
y = a + b₁x₁ + b₂x₂ + … + bₙxₙ
Multiple regression is widely used in data science and predictive analytics.
Differences Between Correlation and Regression
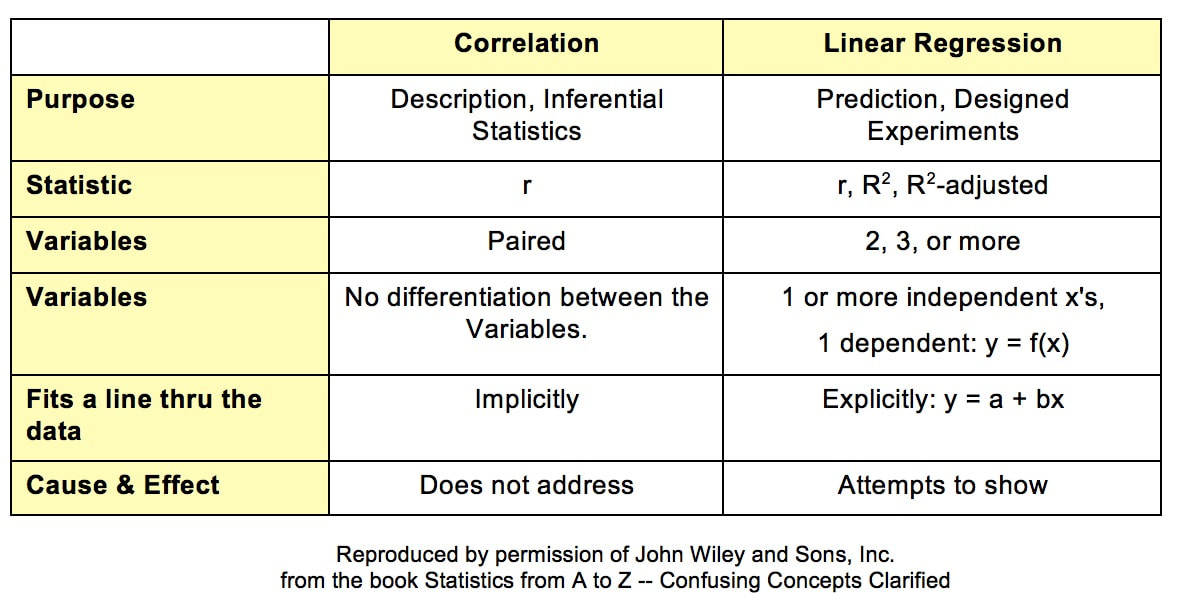
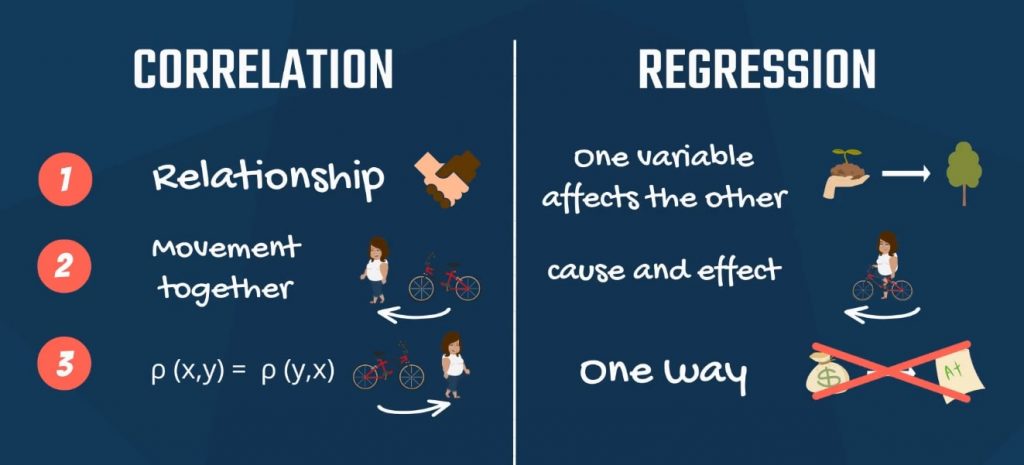

Although correlation and regression are related, they serve different purposes.
Correlation:
- measures strength and direction of relationship
- symmetric relationship
- does not imply causation
Regression:
- models the relationship mathematically
- predicts values of one variable
- distinguishes dependent and independent variables
Thus, correlation describes relationships while regression provides predictive models.
Applications of Regression and Correlation


Regression and correlation are used in many real-world applications.
Economics
Economists study relationships between income, consumption, and investment.
Business
Companies analyze advertising expenditure and sales revenue.
Finance
Investors study relationships between asset prices and market indicators.
Medicine
Researchers analyze relationships between lifestyle factors and health outcomes.
Data Science
Machine learning algorithms use regression models for prediction.
These techniques help analyze complex datasets and identify meaningful relationships.
Importance of Regression and Correlation
Regression and correlation are essential tools in statistical analysis.
They help researchers:
- understand relationships between variables
- predict future outcomes
- identify trends in data
- develop mathematical models
Without these tools, it would be difficult to analyze large datasets and extract useful insights.
These techniques form the foundation of modern statistical modeling.
Conclusion
Regression and correlation are powerful statistical methods used to analyze relationships between variables. Correlation measures the strength and direction of the relationship, while regression provides mathematical models for prediction.
These concepts play a crucial role in mathematics, statistics, economics, business analytics, data science, and scientific research. They allow researchers to analyze patterns, make predictions, and understand complex relationships in data.
By studying regression and correlation, students and researchers gain important analytical tools that help transform raw data into meaningful insights.