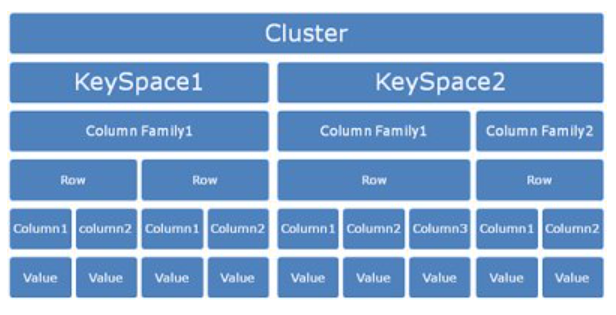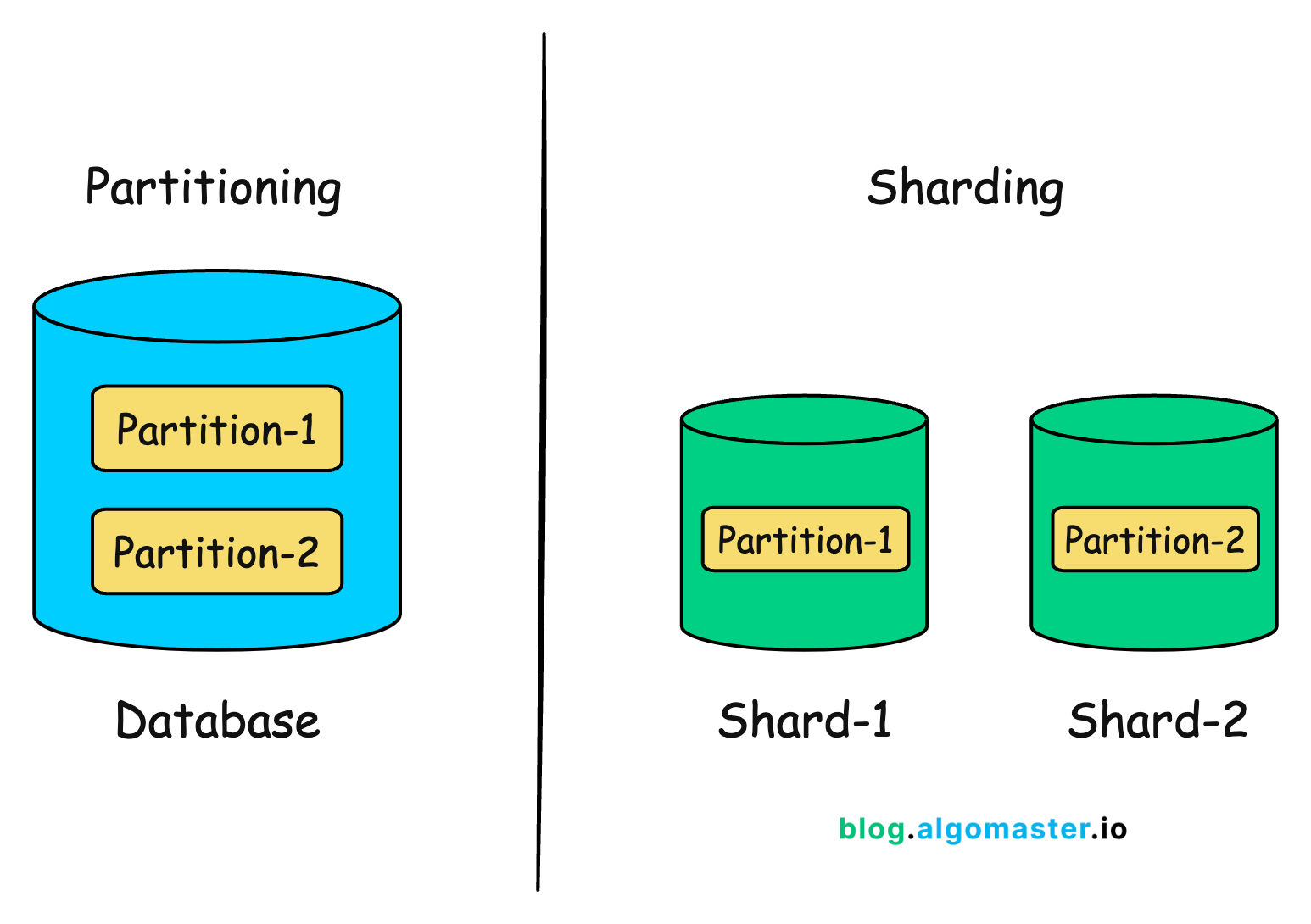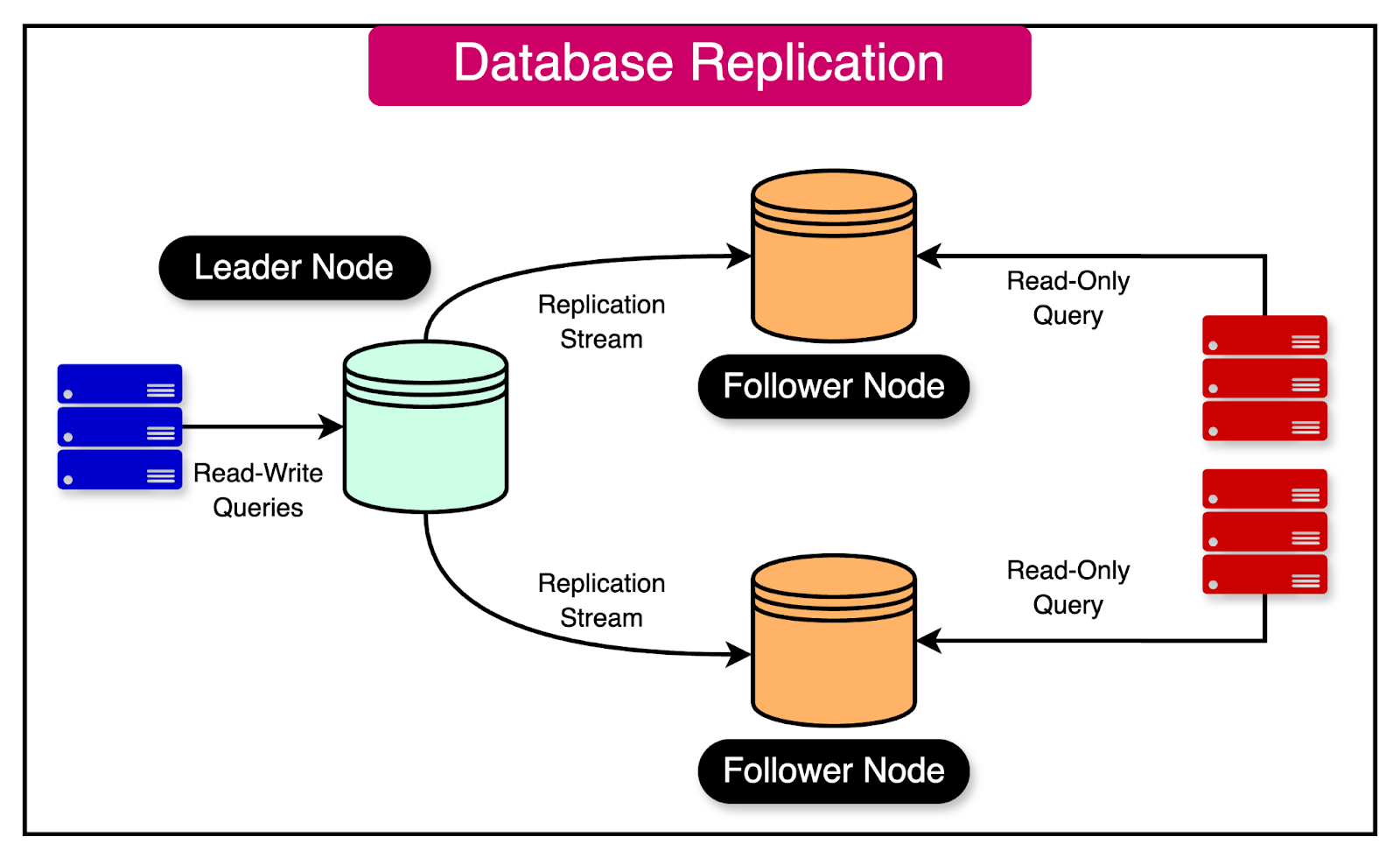
📘 1. Introduction to Data Warehousing
A Data Warehouse is a centralized repository designed to store large volumes of structured data collected from multiple sources for the purpose of analysis, reporting, and decision-making.
Unlike operational databases (OLTP systems), which handle day-to-day transactions, data warehouses are optimized for analytical processing (OLAP).
🔹 Definition
A data warehouse is:
A subject-oriented, integrated, time-variant, and non-volatile collection of data that supports decision-making.
🔹 Key Characteristics
- Subject-Oriented → Organized around business topics (sales, customers)
- Integrated → Combines data from multiple sources
- Time-Variant → Stores historical data
- Non-Volatile → Data is stable (read-heavy, not frequently updated)
🧠 2. Why Data Warehousing is Important
🔹 Business Benefits
- Better decision-making
- Historical trend analysis
- Improved reporting
- Data consistency across organization
🔹 Problems It Solves
- Data scattered across systems
- Inconsistent formats
- Slow reporting queries
- Lack of historical insights
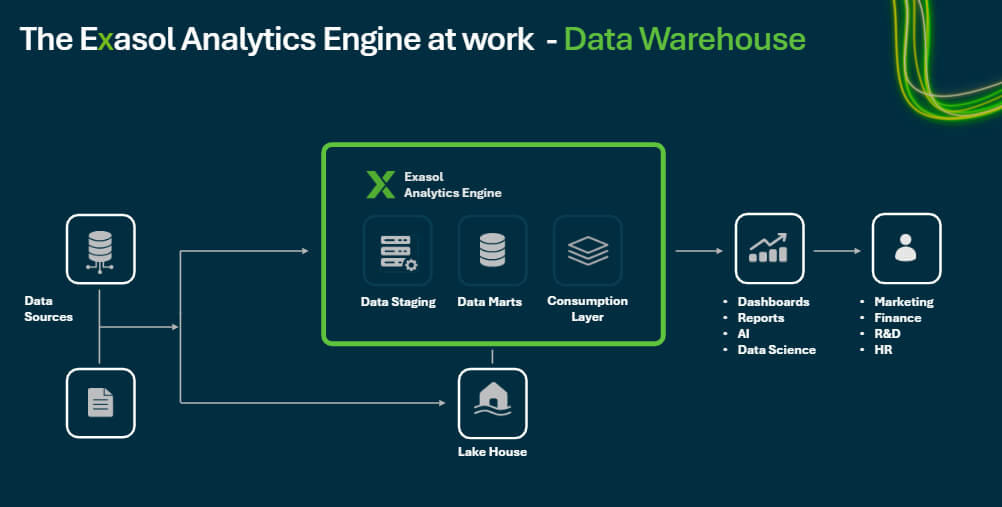
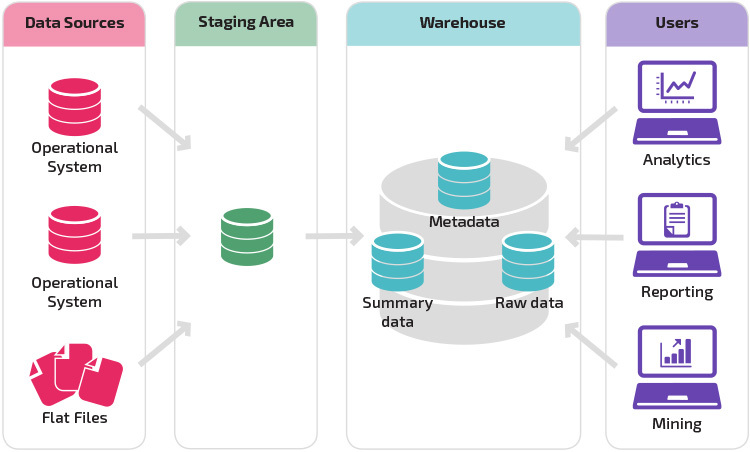
🏗️ 3. Data Warehouse Architecture


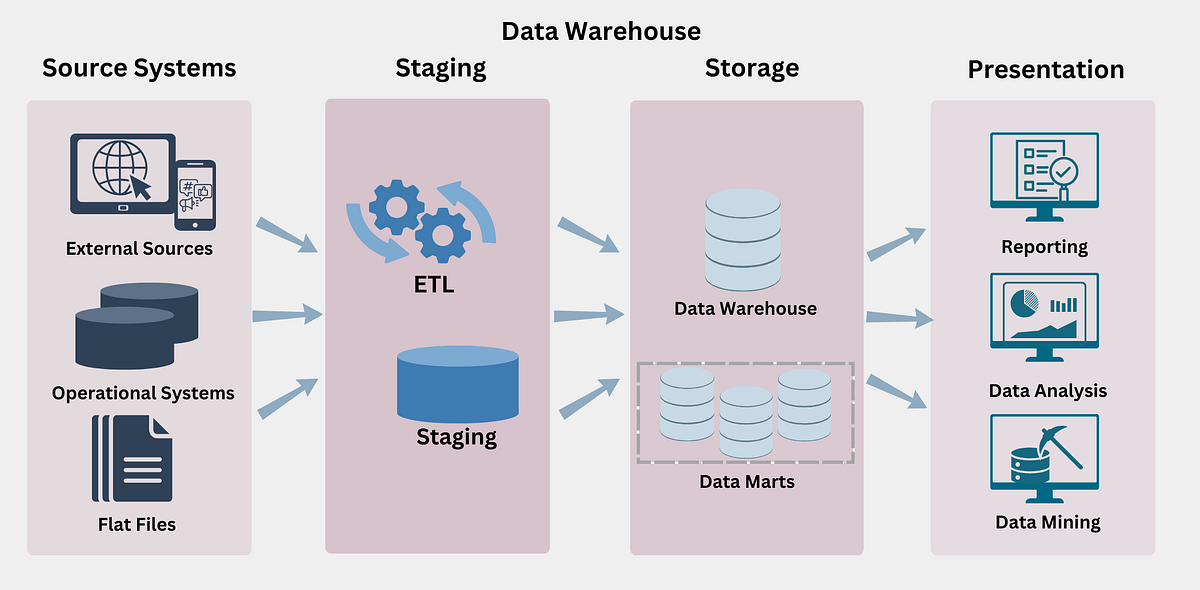

🔹 Three-Tier Architecture
1. Bottom Tier – Data Sources
- Operational databases
- APIs
- Logs
- External data
2. Middle Tier – Data Warehouse Server
- ETL processing
- Storage
- Data integration
3. Top Tier – Front-End Tools
- Reporting tools
- Dashboards
- BI tools
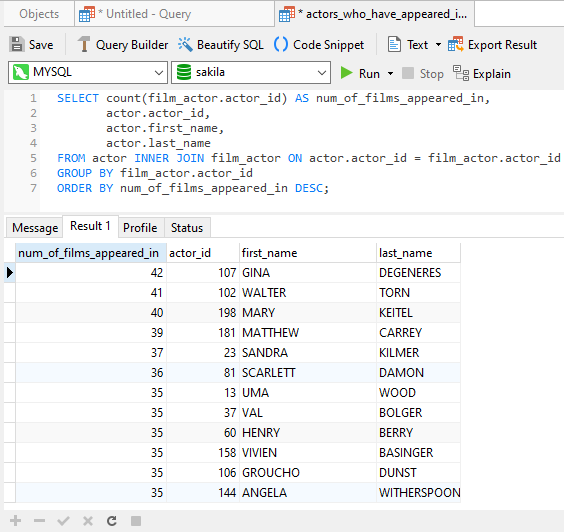
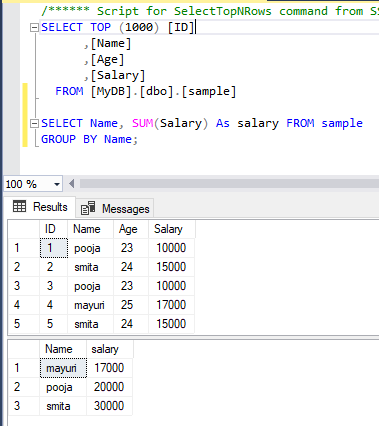
🔄 4. ETL Process (Extract, Transform, Load)

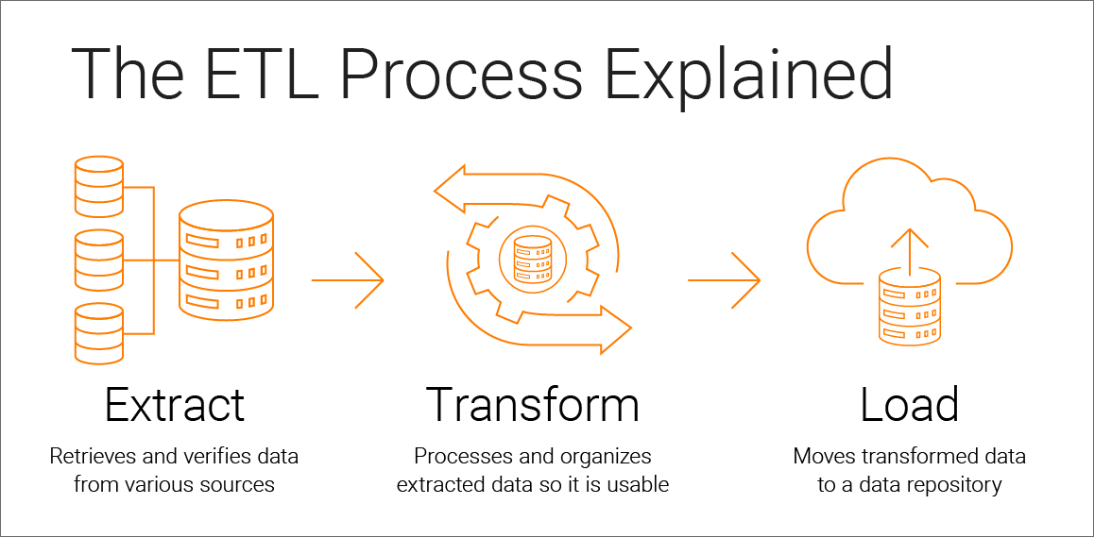
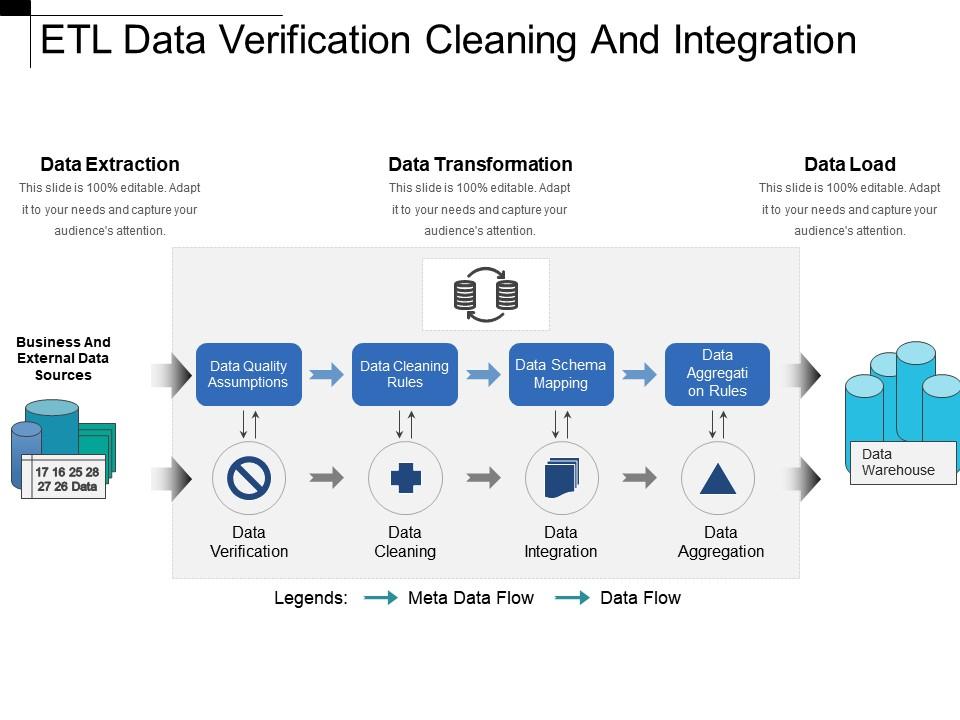

🔹 1. Extract
- Collect data from sources
- Structured and unstructured
🔹 2. Transform
- Clean data
- Normalize formats
- Apply business rules
🔹 3. Load
- Store data into warehouse
🔹 ELT (Modern Approach)
- Load first, transform later
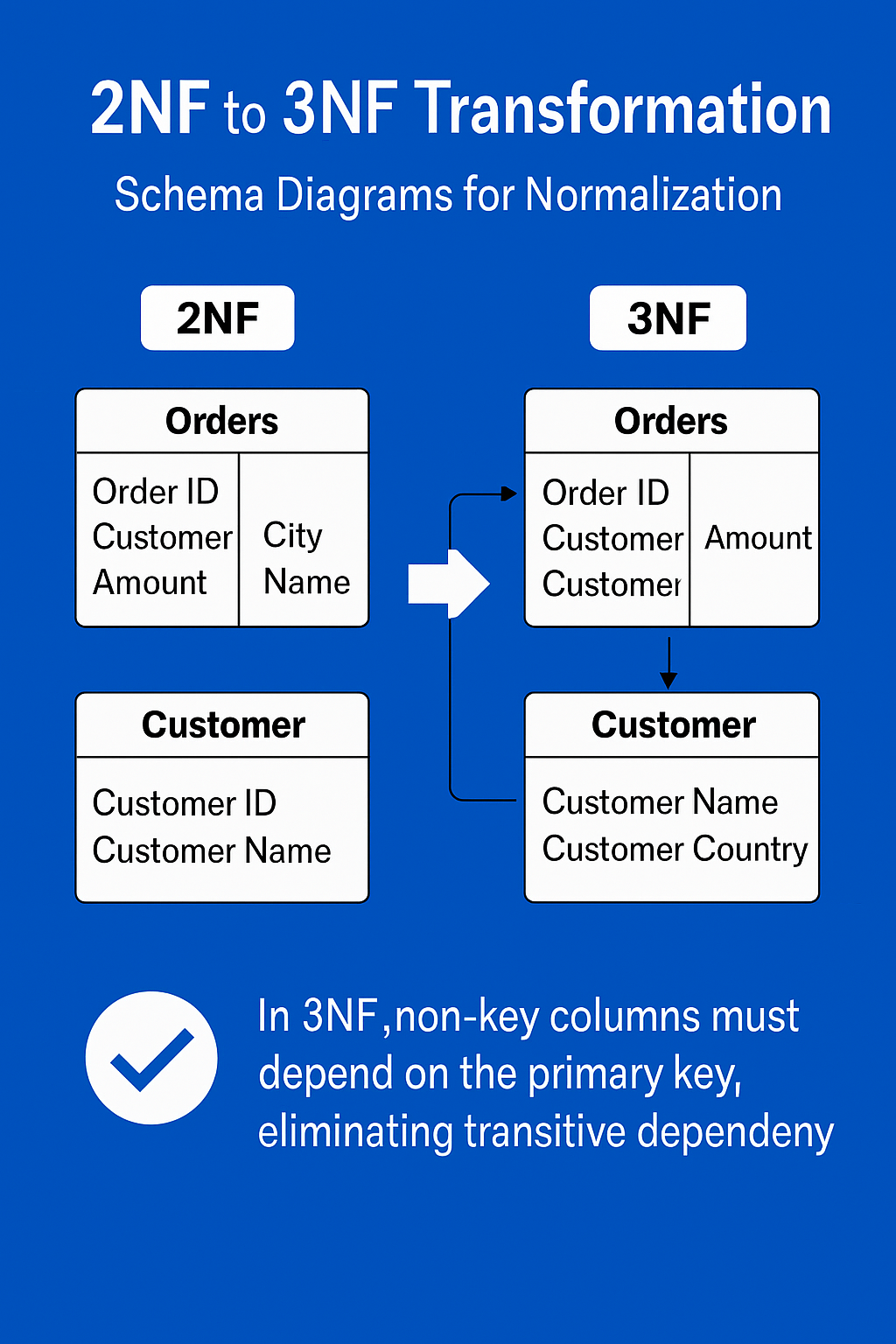
🧩 5. Data Modeling in Warehousing
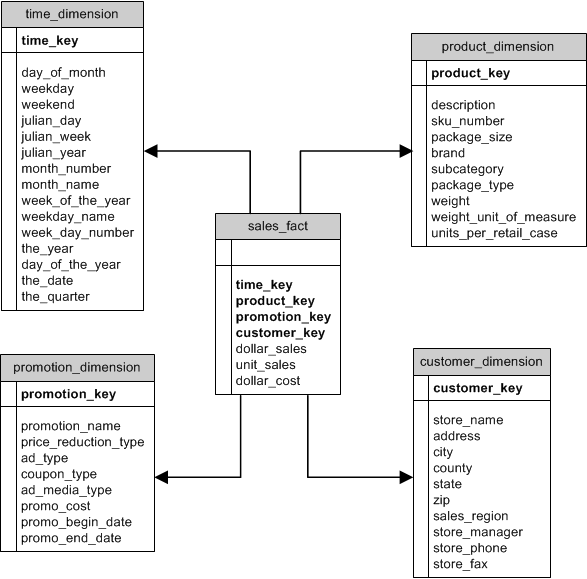


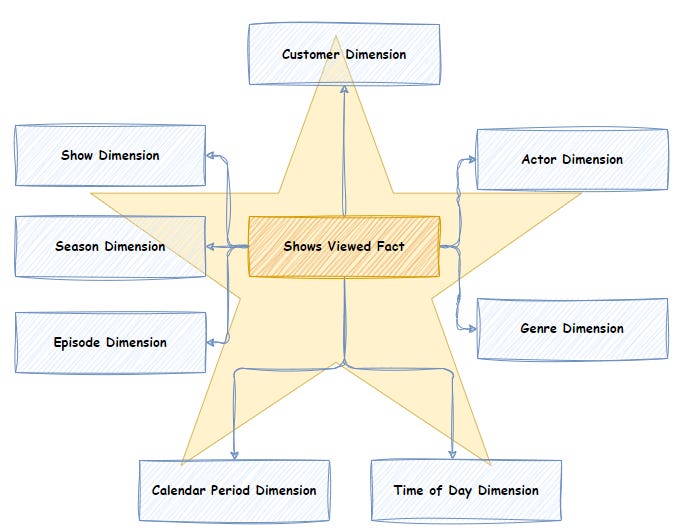
🔹 Types of Models
1. Star Schema ⭐
- Central fact table
- Connected dimension tables
2. Snowflake Schema ❄️
- Normalized dimensions
- More complex
3. Galaxy Schema 🌌
- Multiple fact tables
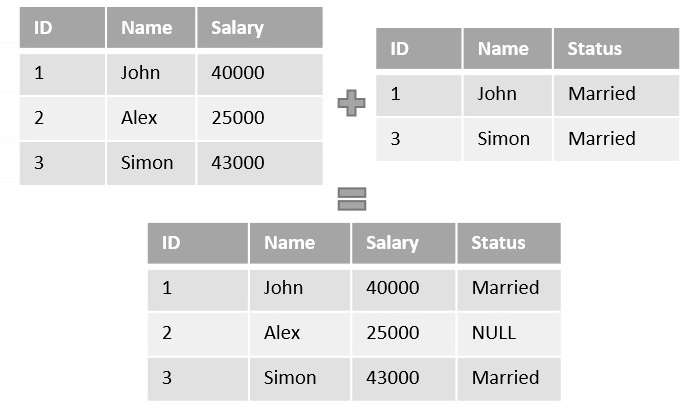
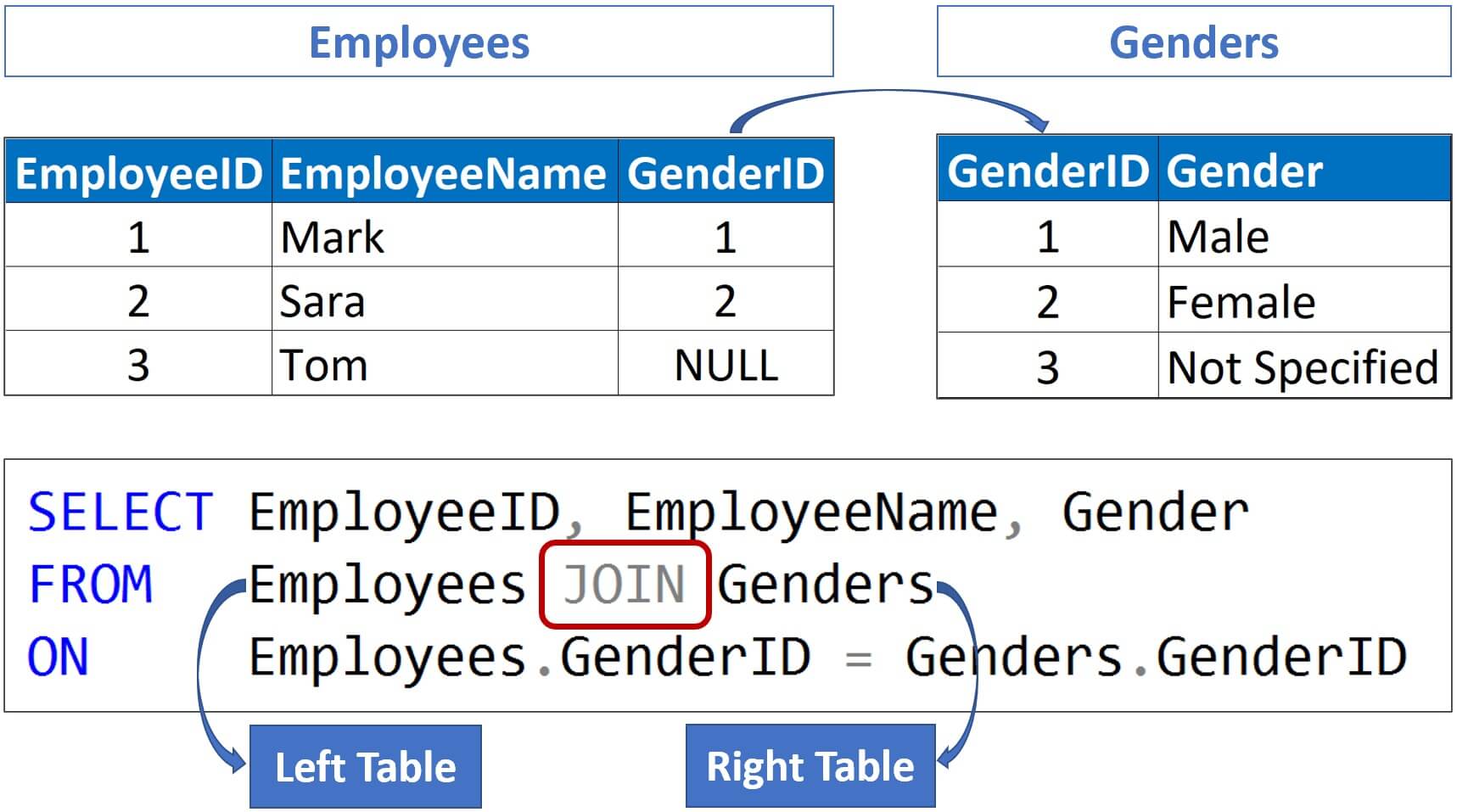
🔹 Fact vs Dimension Tables
| Fact Table | Dimension Table |
|---|---|
| Quantitative data | Descriptive data |
| Sales amount | Customer info |
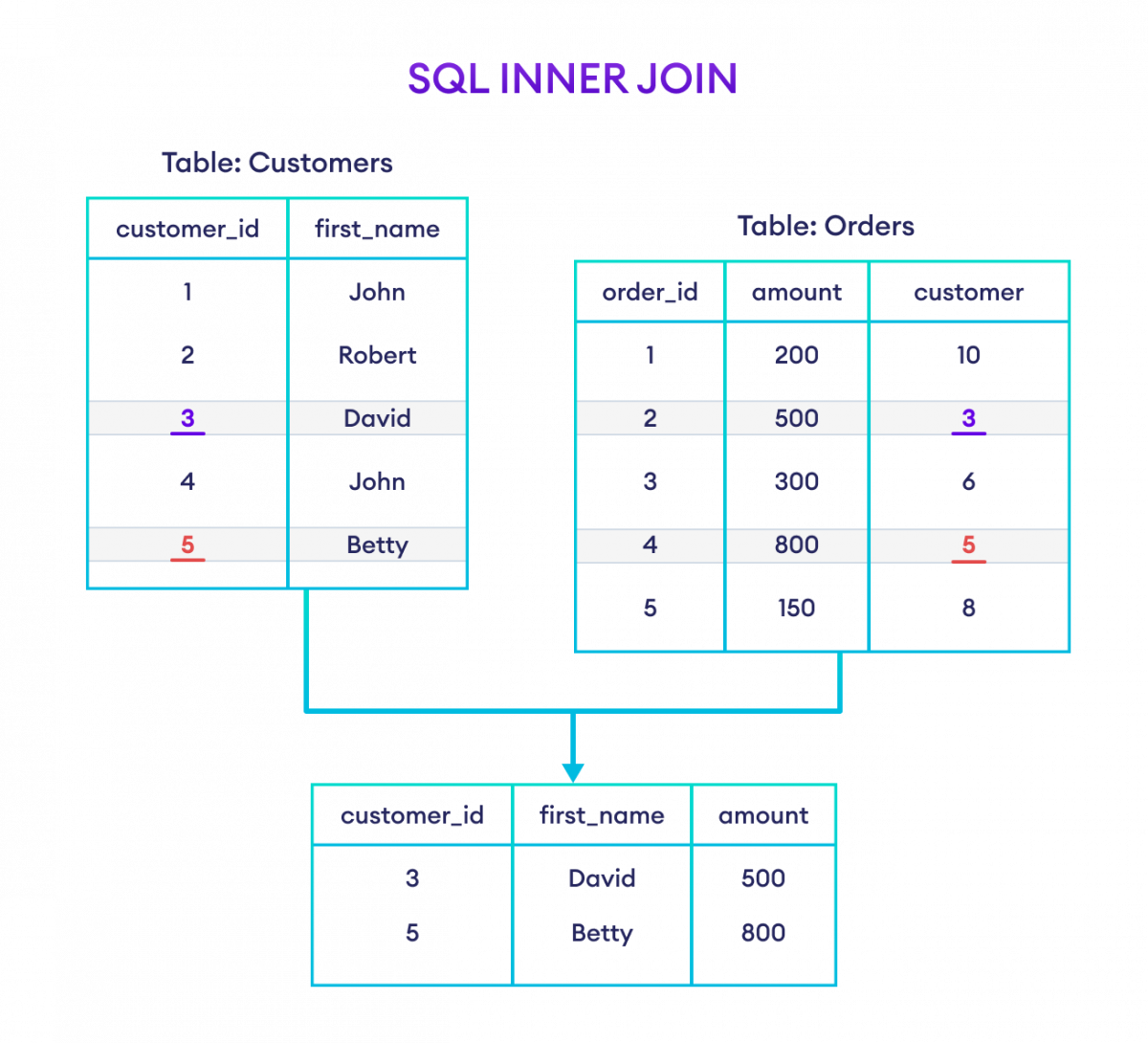
📊 6. OLTP vs OLAP
| Feature | OLTP | OLAP |
|---|---|---|
| Purpose | Transactions | Analysis |
| Data | Current | Historical |
| Queries | Simple | Complex |
🔹 OLAP Operations
- Roll-up
- Drill-down
- Slice
- Dice
🧠 7. Data Marts
🔹 Definition
A data mart is a subset of a data warehouse focused on a specific department.
🔹 Types
- Dependent
- Independent
- Hybrid
⚡ 8. Data Warehouse Design Approaches
🔹 Top-Down (Inmon)
- Build enterprise warehouse first
🔹 Bottom-Up (Kimball)
- Build data marts first
🔐 9. Data Quality and Governance
🔹 Data Quality
- Accuracy
- Completeness
- Consistency
🔹 Governance
- Policies
- Standards
- Data ownership
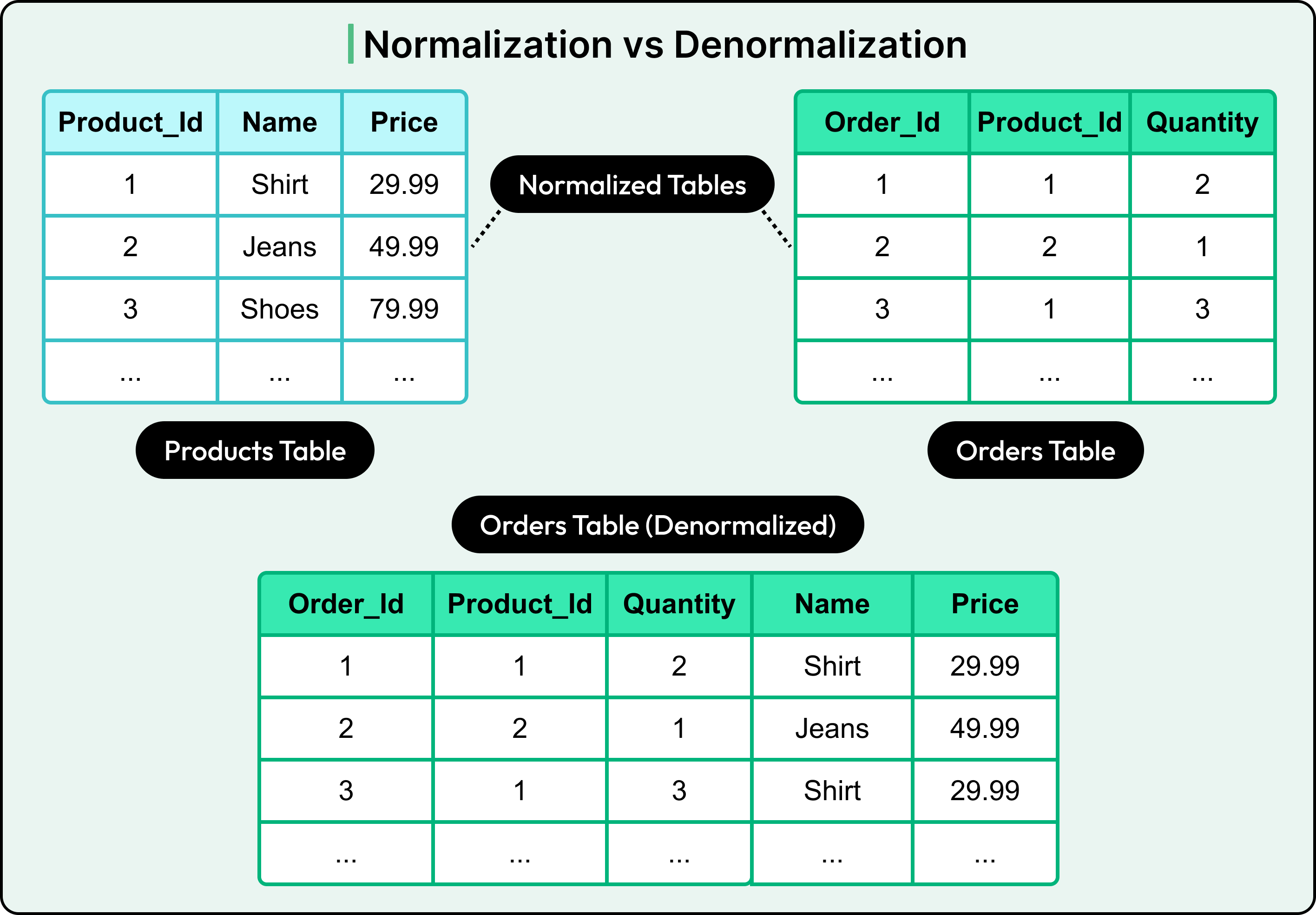
🔄 10. Data Integration
🔹 Methods
- ETL
- ELT
- Data virtualization
🌐 11. Data Warehousing in Cloud
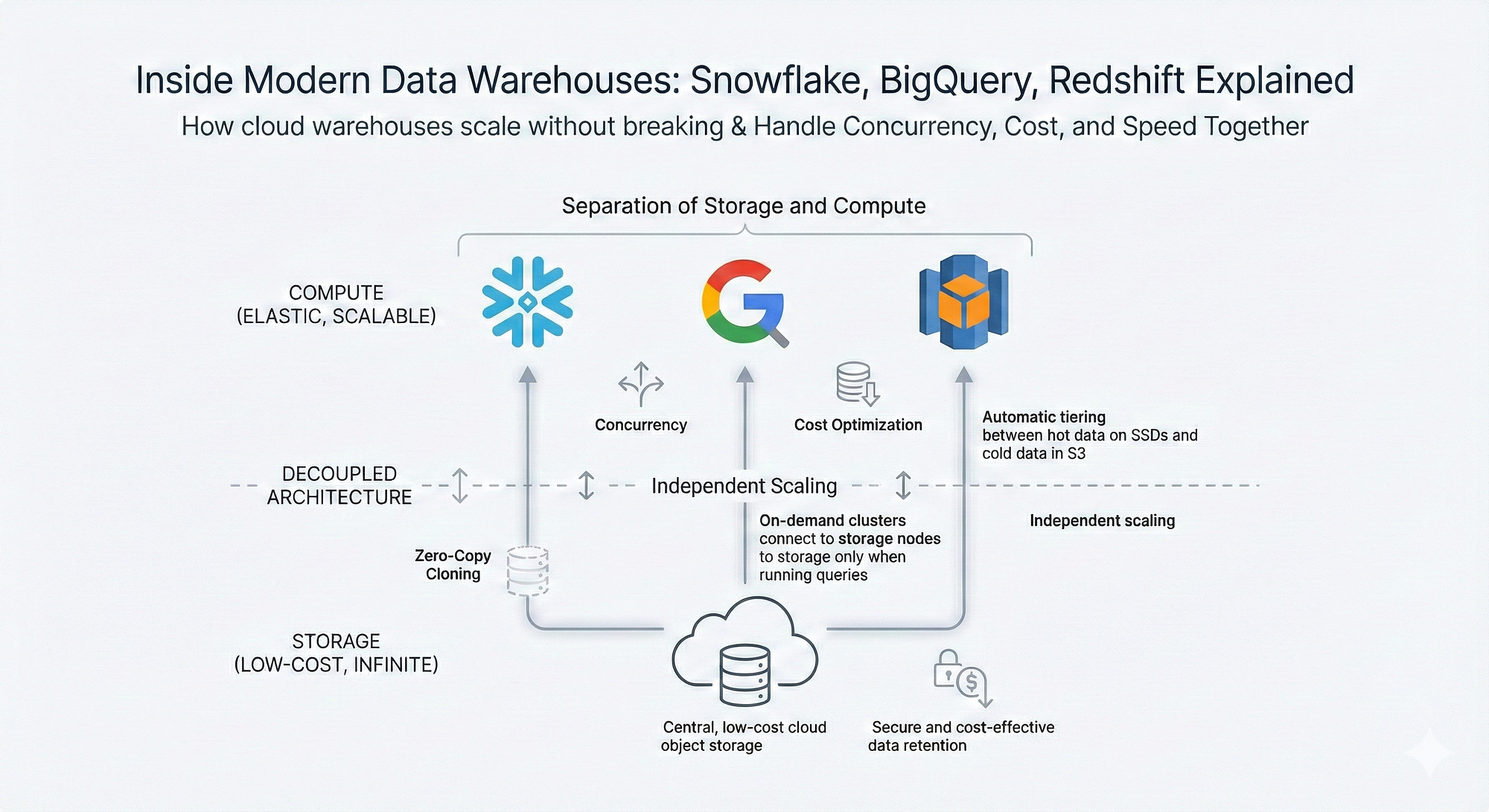
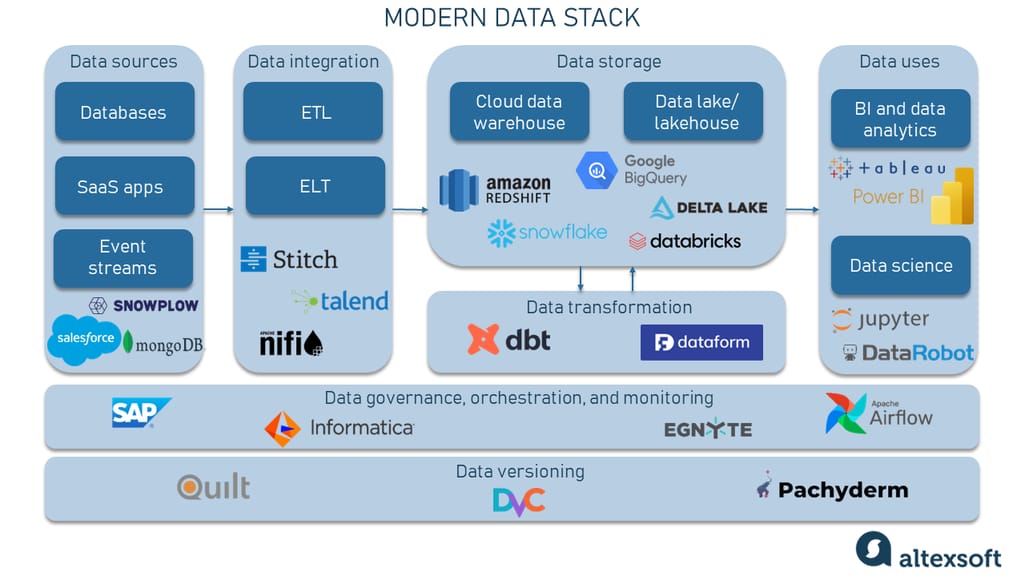
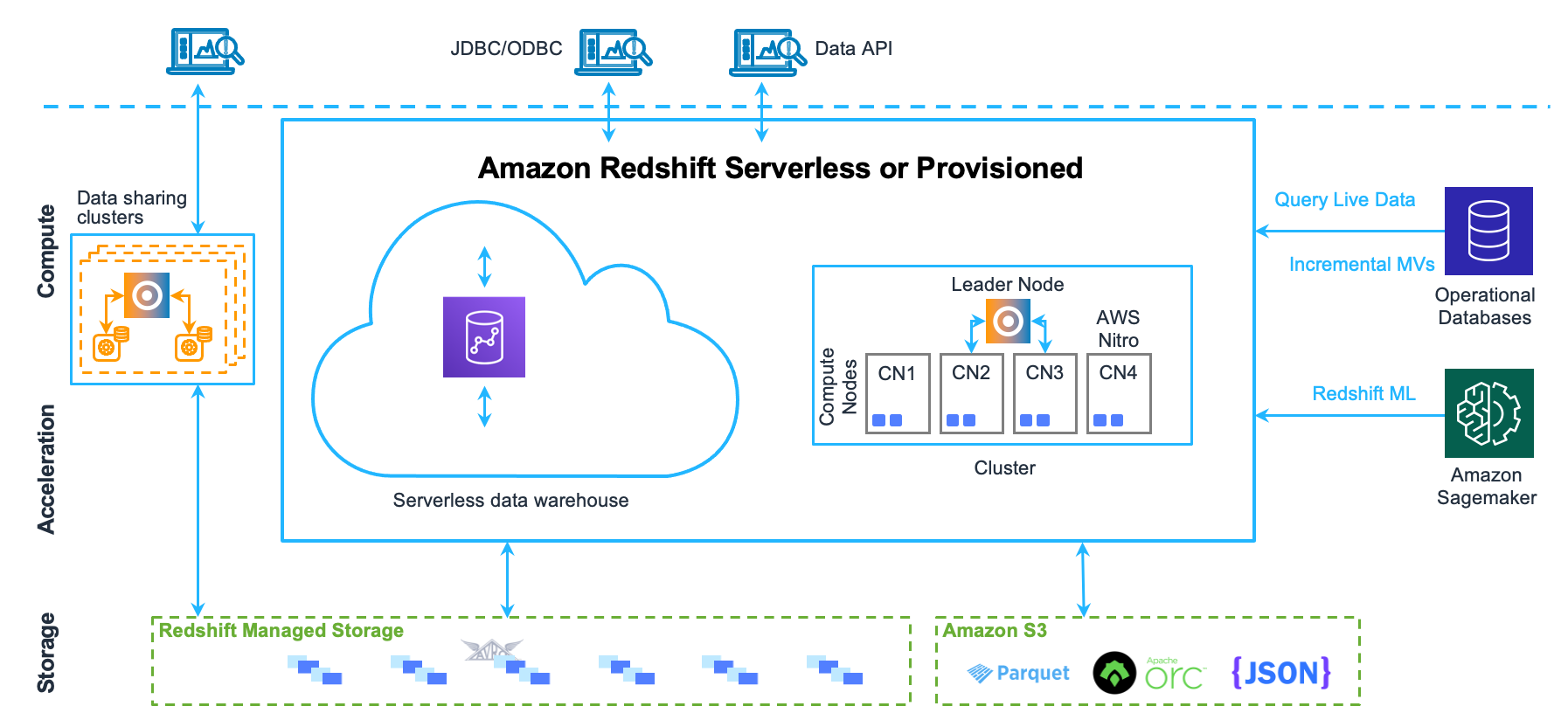
🔹 Features
- Scalability
- Cost efficiency
- Managed services
🔹 Examples
- Cloud warehouses
- Serverless systems
🧪 12. Data Warehouse Tools
- ETL tools
- BI tools
- Data modeling tools
📈 13. Performance Optimization
🔹 Techniques
- Indexing
- Partitioning
- Materialized views
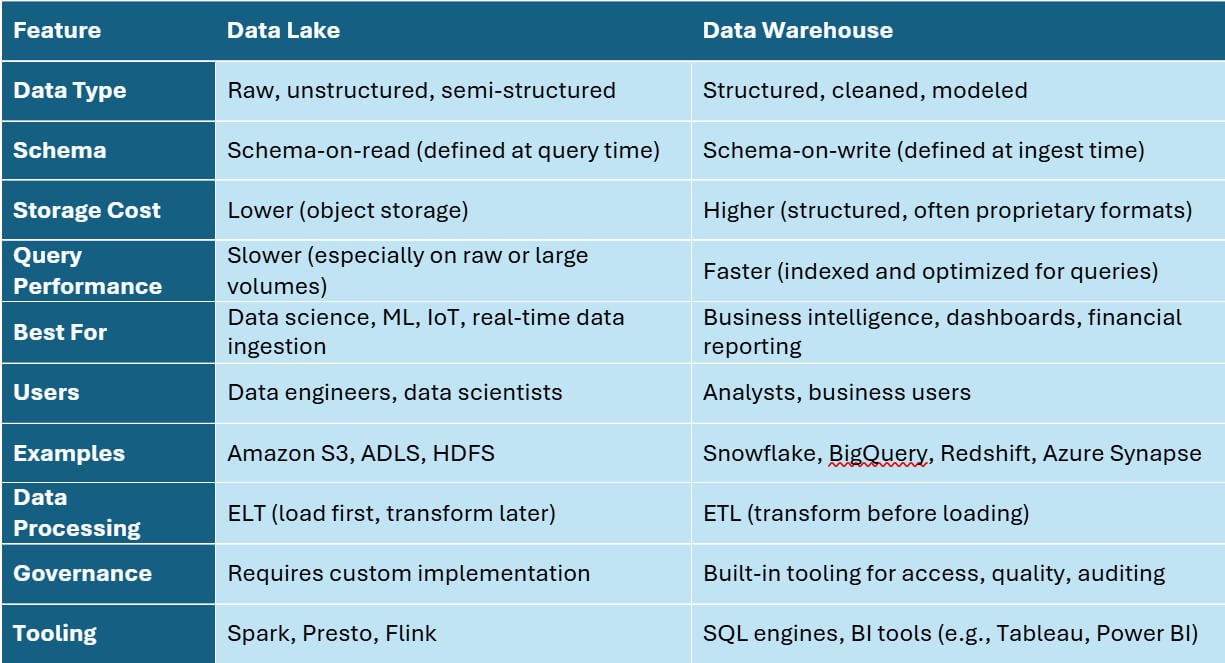
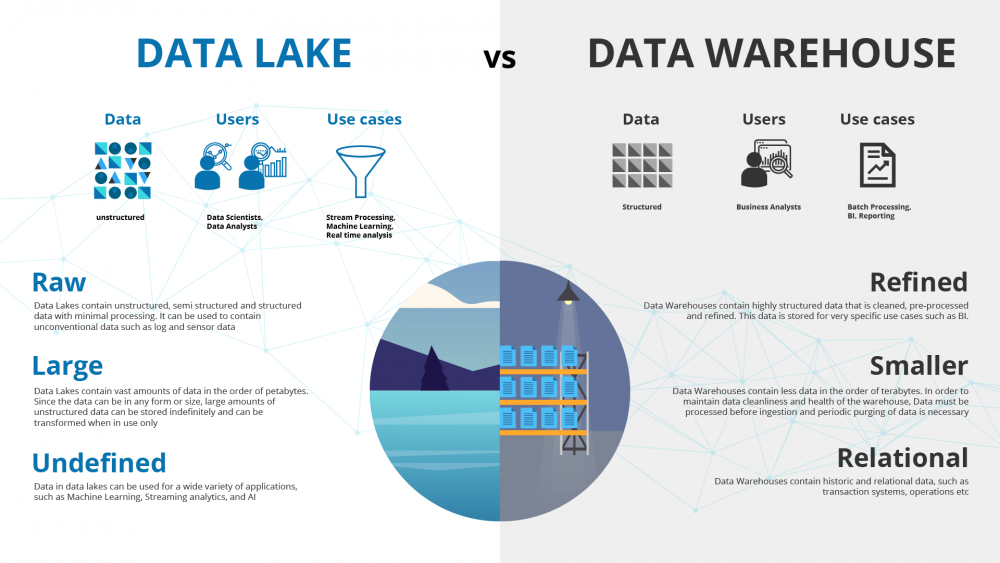
🧩 14. Data Warehouse vs Data Lake
| Feature | Data Warehouse | Data Lake |
|---|---|---|
| Data | Structured | Raw |
| Schema | Fixed | Flexible |
🔄 15. Data Pipeline
🔹 Components
- Ingestion
- Processing
- Storage
- Visualization
🧠 16. Big Data and Warehousing
- Integration with Hadoop
- Spark processing
- Real-time analytics
🔐 17. Security in Data Warehousing
- Encryption
- Access control
- Auditing
📊 18. Real-World Applications
🔹 Retail
- Sales analysis
🔹 Banking
- Risk analysis
🔹 Healthcare
- Patient analytics
🔹 Marketing
- Customer insights
⚖️ 19. Advantages
- Better analytics
- Historical insights
- Centralized data
⚠️ 20. Limitations
- High cost
- Complex setup
- Maintenance required
🔮 21. Future Trends
- AI-driven analytics
- Real-time warehousing
- Data lakehouse
🏁 Conclusion
Data warehousing is a core component of modern data ecosystems, enabling organizations to transform raw data into meaningful insights. It plays a critical role in business intelligence, analytics, and strategic decision-making.