

📘 1. Introduction to Transactions
A transaction in database systems is a sequence of one or more operations performed as a single logical unit of work. These operations may include:
- Reading data
- Writing data
- Updating records
- Deleting records
The key idea is simple but powerful:
👉 Either all operations succeed, or none of them do.
🔹 Real-Life Example
Consider a bank transfer:
- Deduct ₹1000 from Account A
- Add ₹1000 to Account B
If step 1 succeeds but step 2 fails, the system becomes inconsistent. Transactions prevent this by ensuring all-or-nothing execution.
🔹 Formal Definition
A transaction is:
- A logical unit of work
- Executed completely or not at all
- Ensures database consistency
🧠 2. Why Transactions Are Important
Transactions are critical for:
- Data integrity
- Reliability
- Consistency across operations
- Handling system failures
- Concurrent access management
🔹 Without Transactions
- Partial updates
- Data corruption
- Lost data
- Inconsistent state
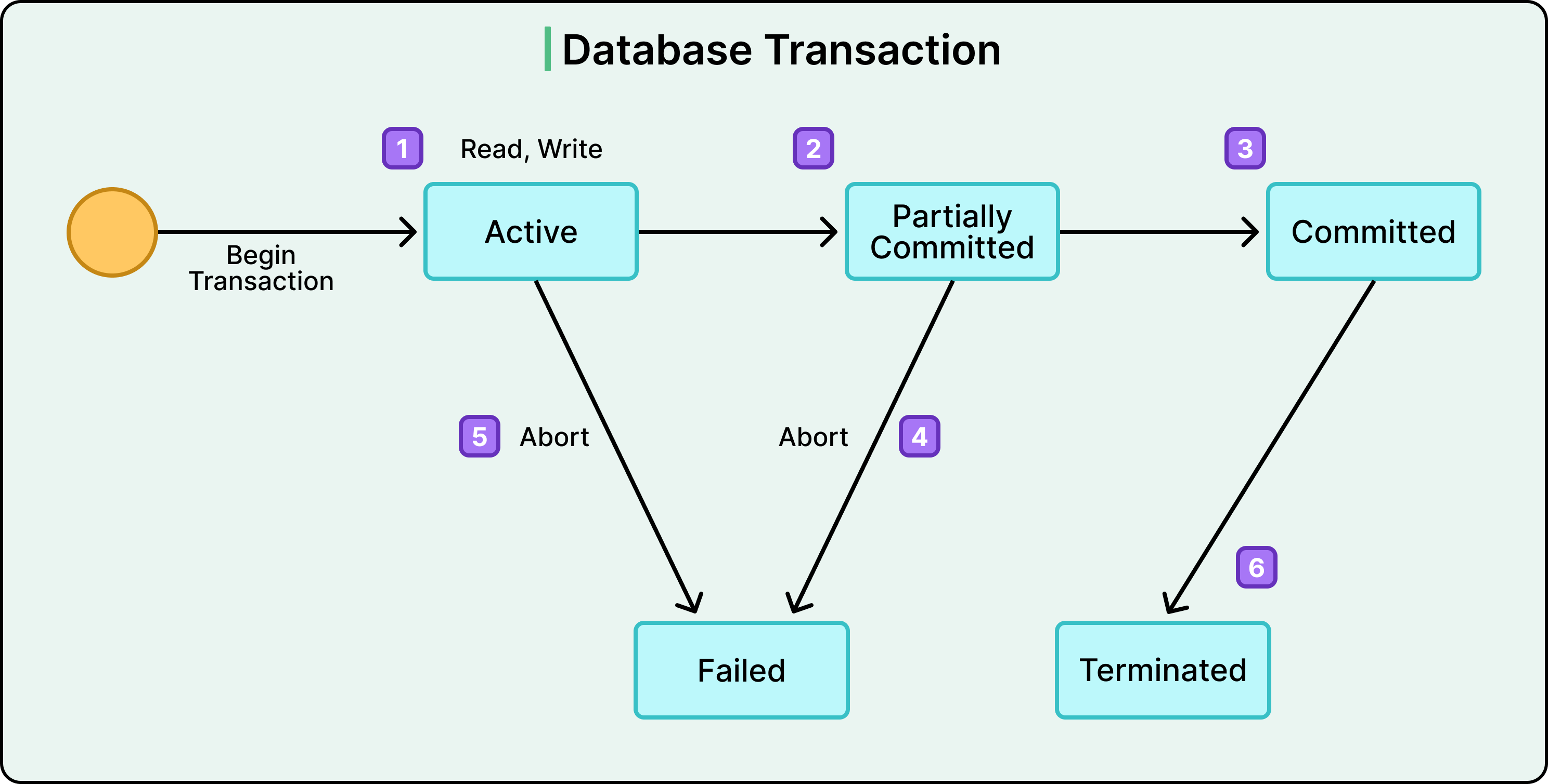
🏗️ 3. Transaction States
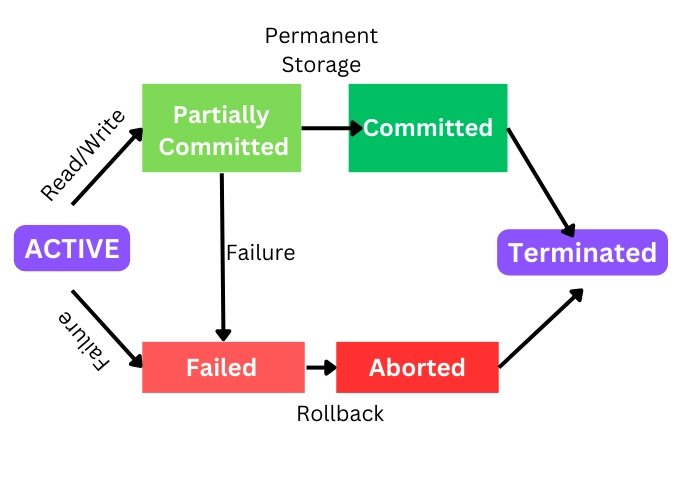

A transaction passes through several states:
🔹 1. Active
- Transaction is executing
🔹 2. Partially Committed
- All operations executed, waiting to commit
🔹 3. Committed
- Changes permanently saved
🔹 4. Failed
- Error occurs
🔹 5. Aborted
- Rolled back to previous state
🔁 4. Transaction Operations
🔹 BEGIN TRANSACTION
Starts a transaction.
BEGIN;
🔹 COMMIT
Saves changes permanently.
COMMIT;
🔹 ROLLBACK
Reverts changes.
ROLLBACK;
🔹 SAVEPOINT
Creates checkpoints.
SAVEPOINT sp1;
ROLLBACK TO sp1;
⚖️ 5. ACID Properties
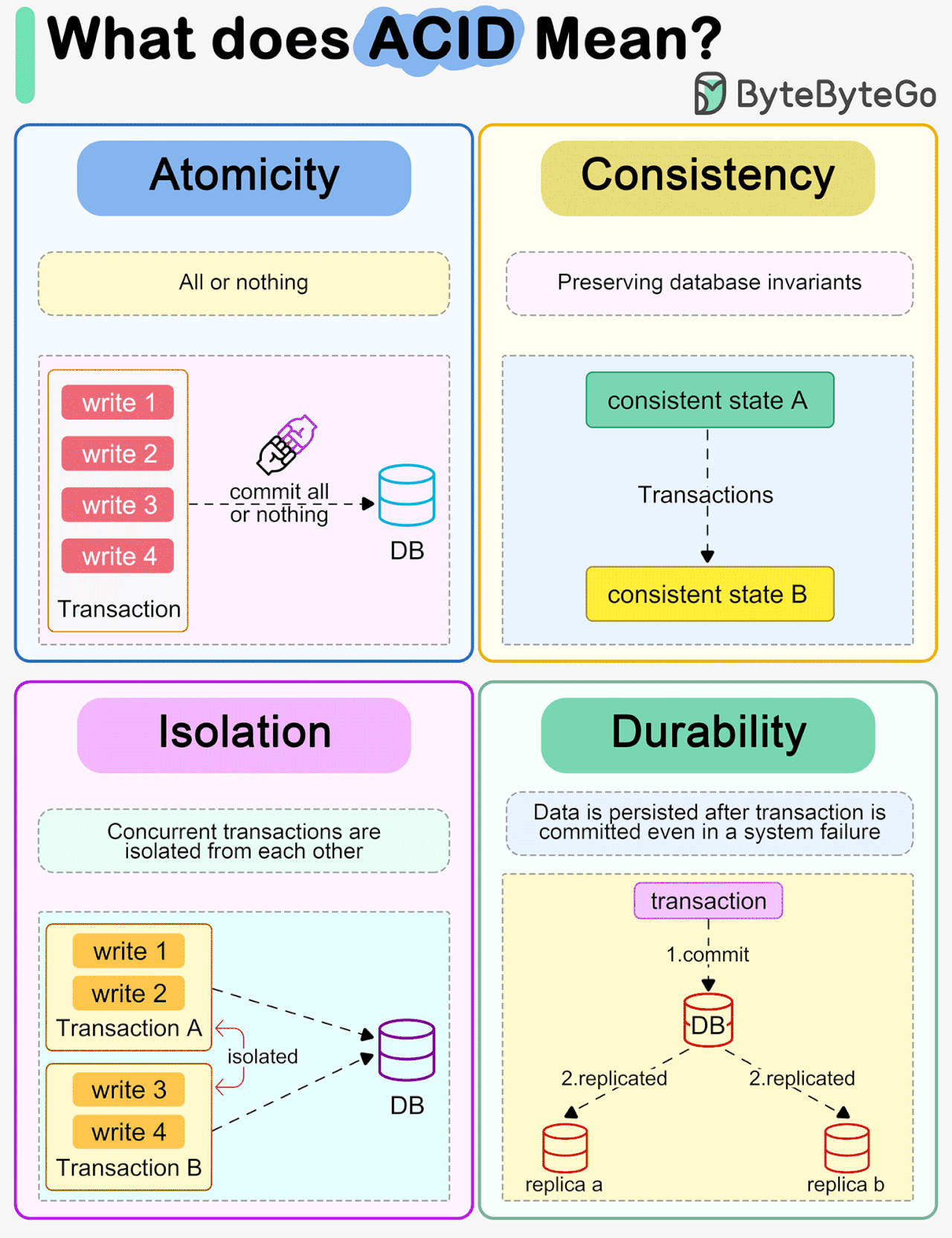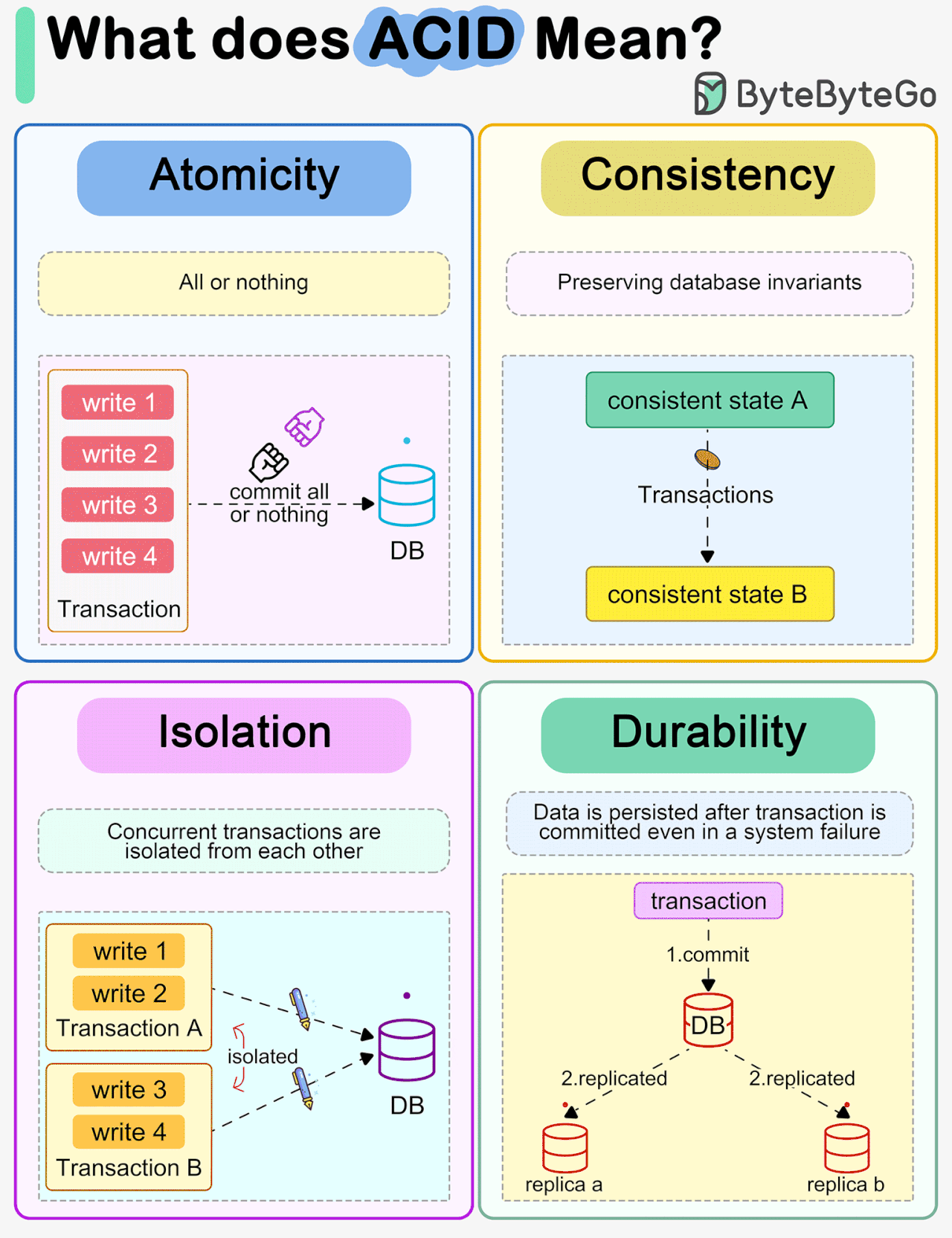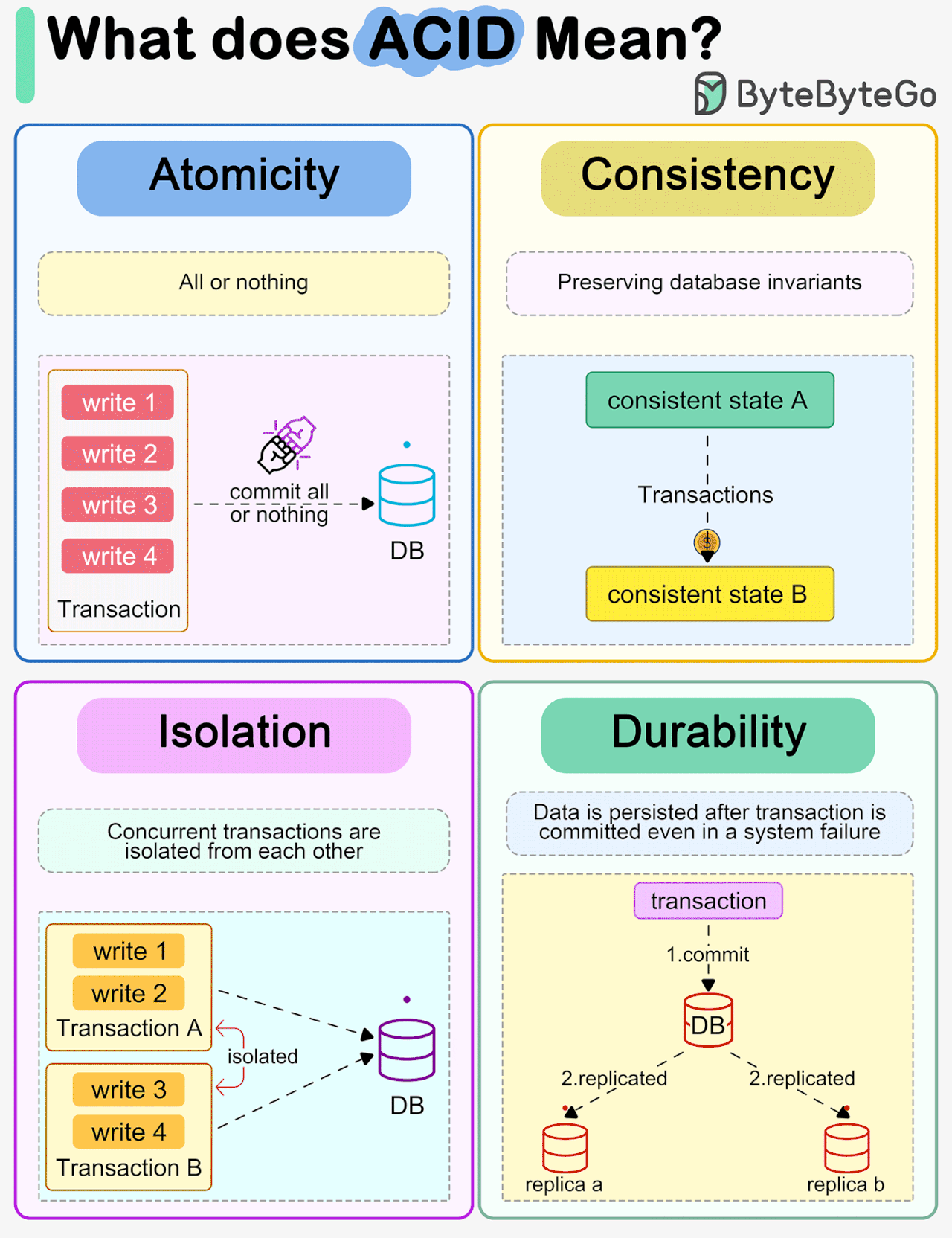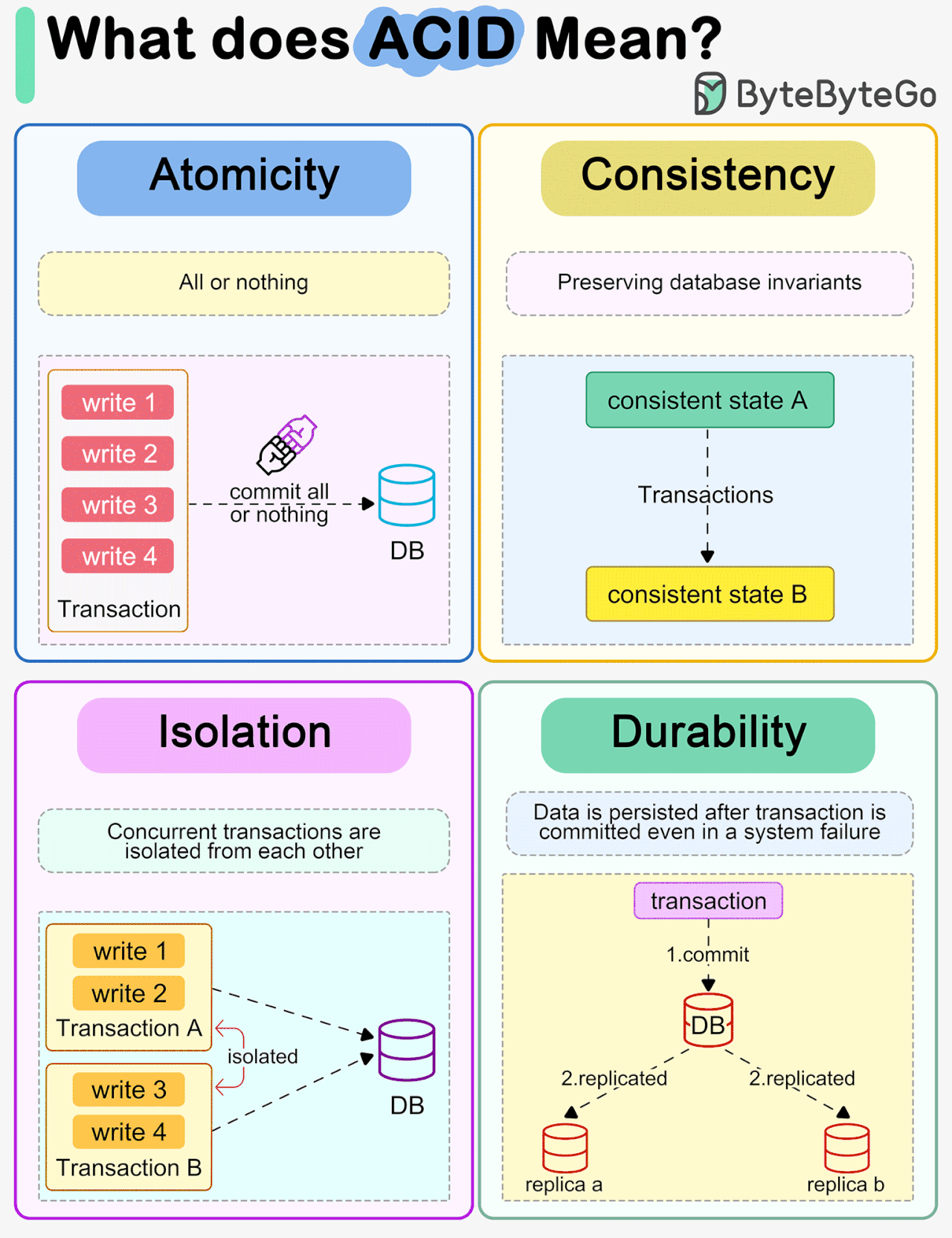

ACID properties ensure reliable transactions:
🔹 A – Atomicity
👉 All or nothing
- If one operation fails → entire transaction fails
- Ensures no partial updates
Example:
- Money deducted but not added → rollback
🔹 C – Consistency
👉 Database remains valid
- Enforces rules, constraints
- Moves from one valid state to another
🔹 I – Isolation
👉 Transactions do not interfere
- Concurrent transactions behave independently
🔹 D – Durability
👉 Changes are permanent
- Even after crash, data persists
🔍 6. Atomicity in Detail
Atomicity ensures:
- No partial execution
- Rollback on failure
🔹 Implementation Techniques
- Undo logs
- Write-ahead logging (WAL)
🔹 Example
BEGIN;
UPDATE Accounts SET balance = balance - 1000 WHERE id = 1;
UPDATE Accounts SET balance = balance + 1000 WHERE id = 2;
COMMIT;
If second update fails → rollback entire transaction.
🧩 7. Consistency in Detail
Consistency ensures:
- Constraints are maintained
- Rules are enforced
🔹 Types of Constraints
- Primary key
- Foreign key
- Check constraints
🔹 Example
- Balance cannot be negative
- Foreign key must exist
🔄 8. Isolation in Detail
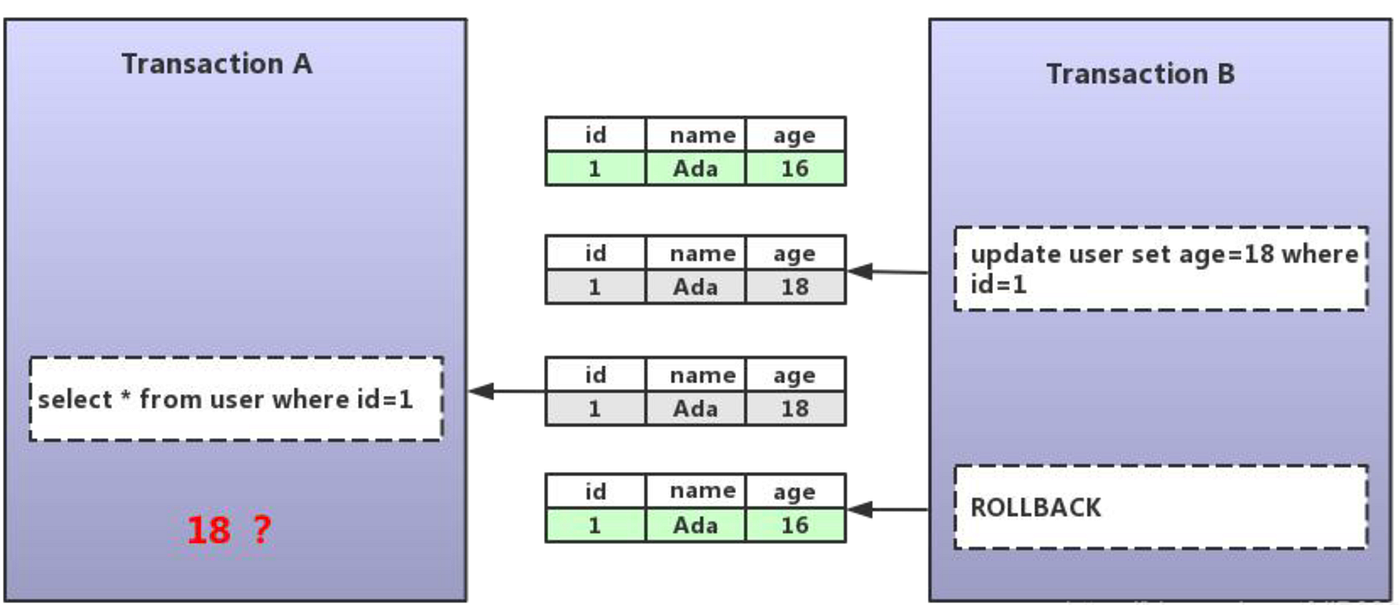

Isolation prevents interference between transactions.
🔹 Problems Without Isolation
1. Dirty Read
Reading uncommitted data
2. Non-repeatable Read
Data changes between reads
3. Phantom Read
New rows appear unexpectedly
🔹 Isolation Levels
| Level | Description |
|---|---|
| Read Uncommitted | Lowest isolation |
| Read Committed | Prevents dirty reads |
| Repeatable Read | Prevents non-repeatable reads |
| Serializable | Highest isolation |
🔐 9. Durability in Detail
Durability ensures:
- Data survives crashes
- Stored permanently
🔹 Implementation
- Transaction logs
- Disk storage
- Backup systems
🔹 Example
After COMMIT:
- Power failure occurs
- Data still exists
🧠 10. Concurrency Control



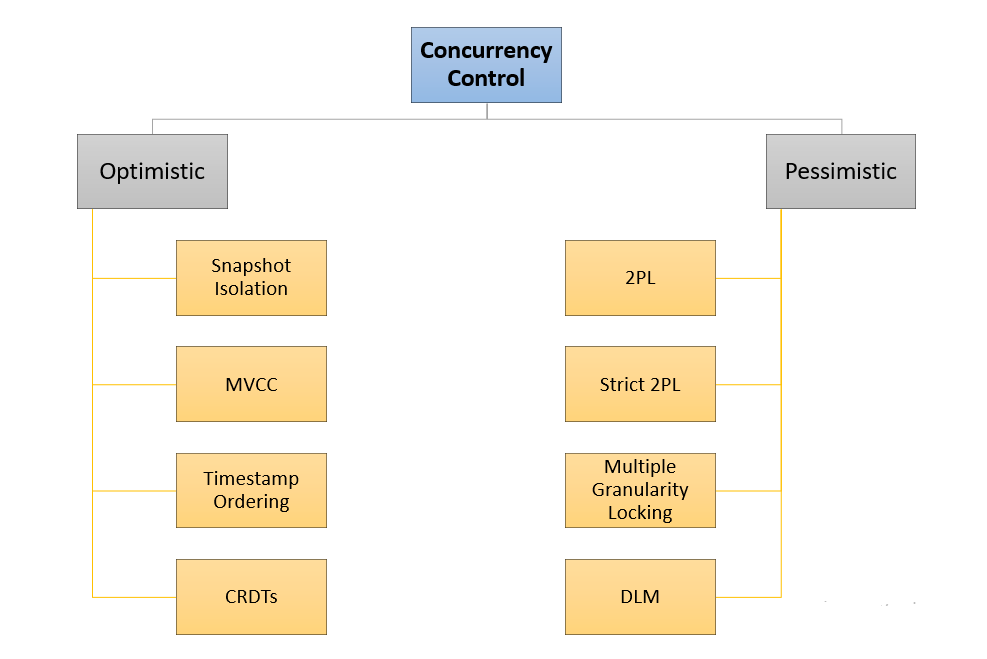
Concurrency control manages multiple transactions.
🔹 Techniques
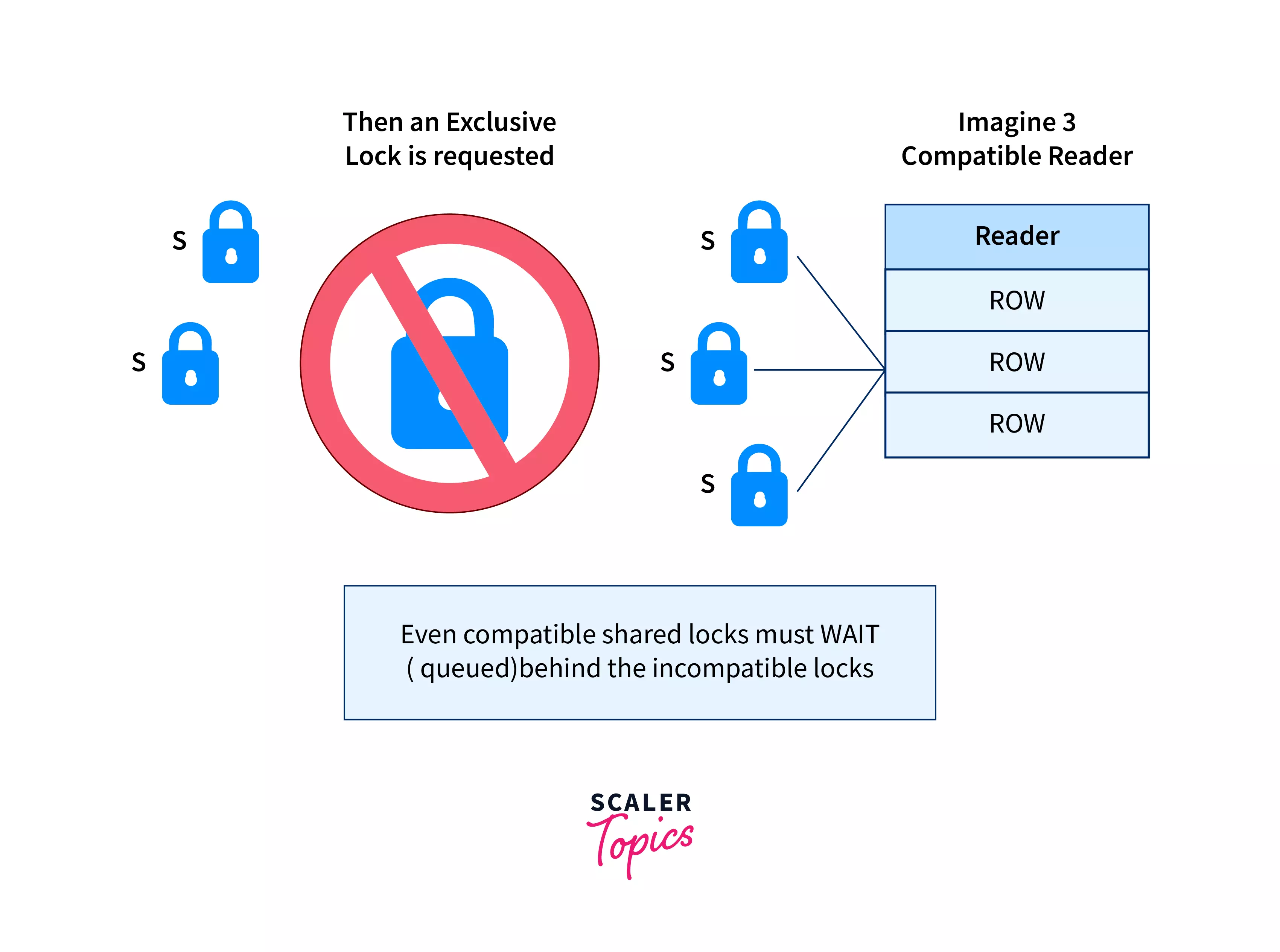
1. Locking
- Shared lock (read)
- Exclusive lock (write)
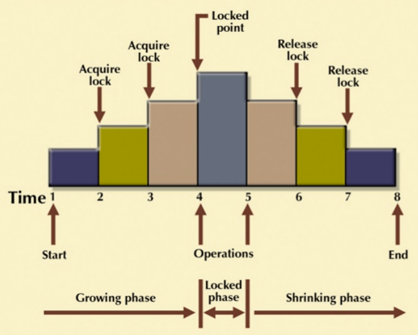
2. Two-Phase Locking (2PL)
- Growing phase
- Shrinking phase
3. Timestamp Ordering
- Based on timestamps
4. MVCC (Multi-Version Concurrency Control)
- Multiple versions of data
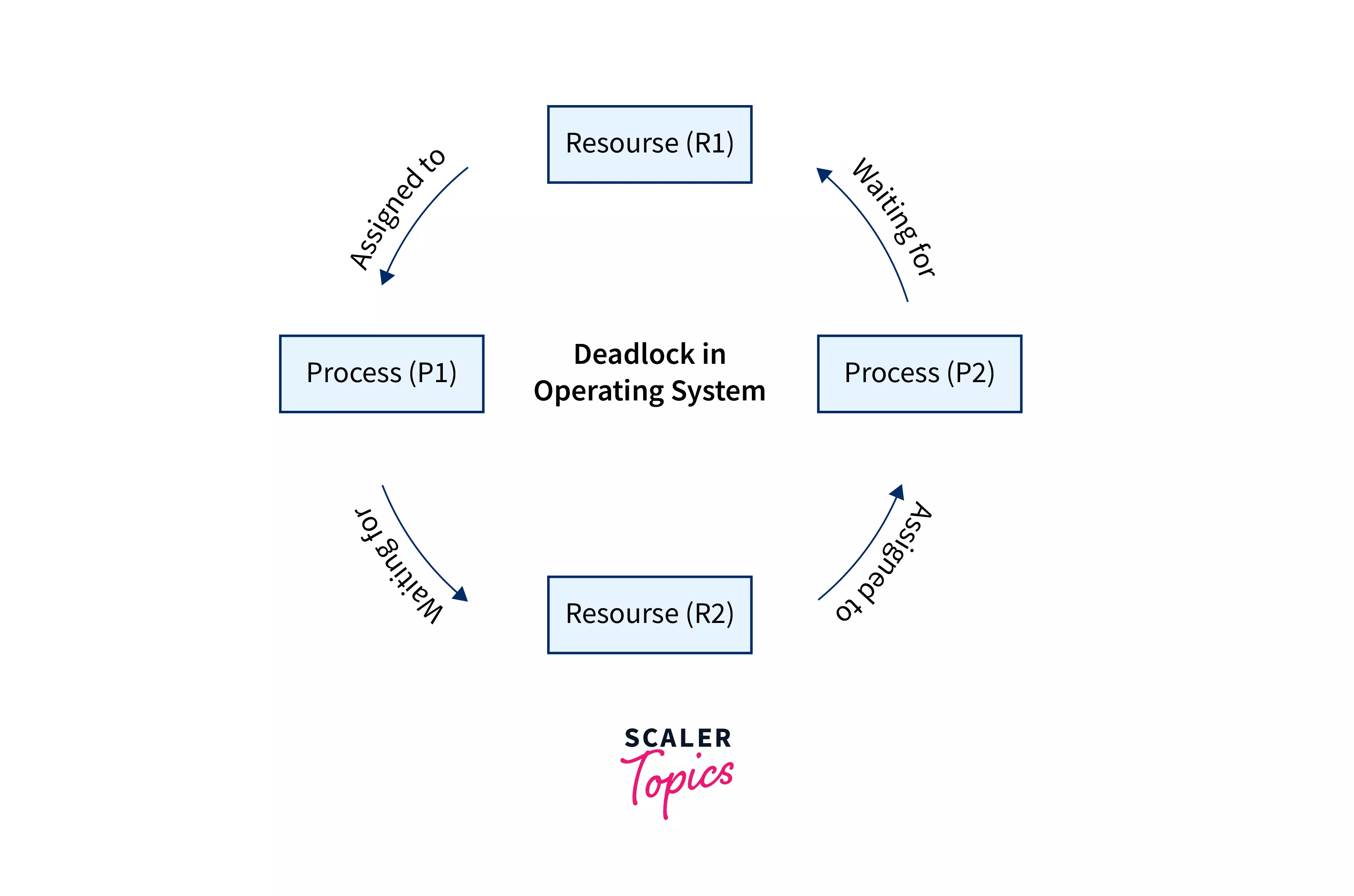
🔁 11. Deadlocks
🔹 What is Deadlock?
Two transactions wait for each other indefinitely.
🔹 Example
- T1 locks A, needs B
- T2 locks B, needs A
🔹 Handling Deadlocks
- Detection
- Prevention
- Timeout
🧪 12. Logging and Recovery

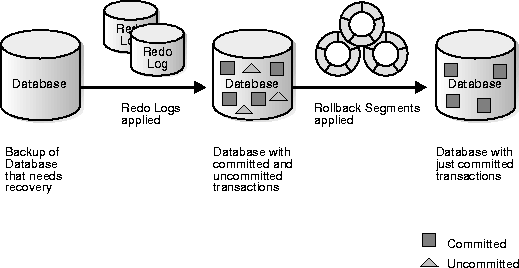
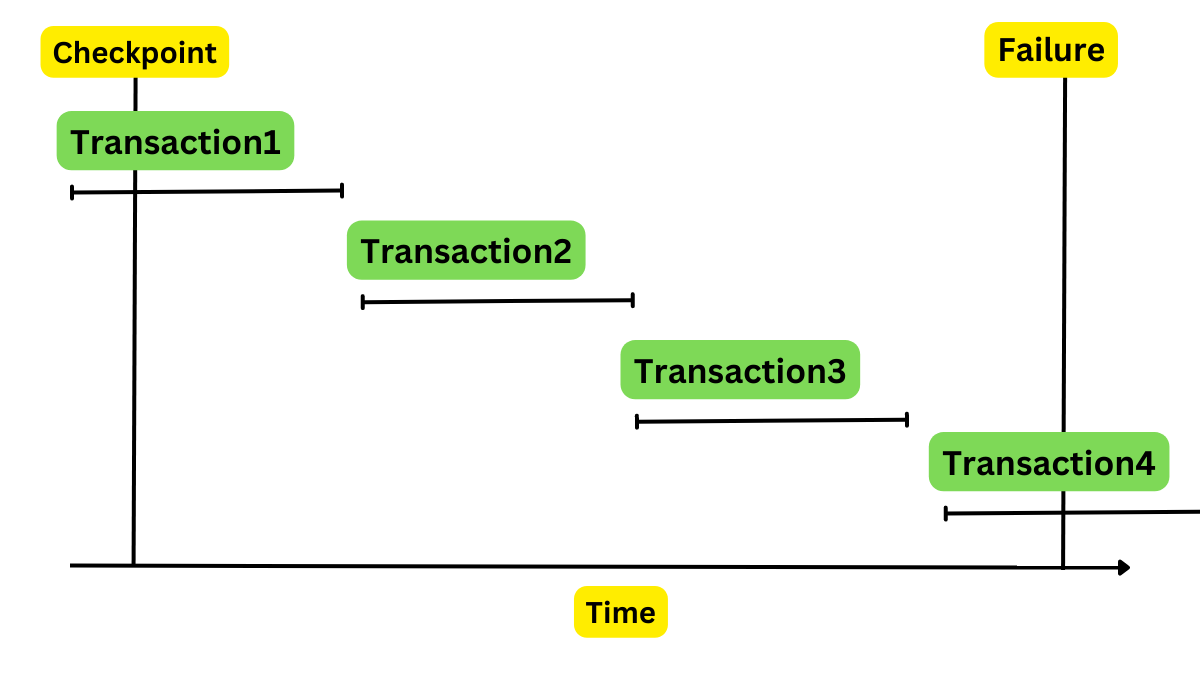
🔹 Types of Logs
- Undo log
- Redo log
🔹 Recovery Techniques
- Checkpointing
- Log-based recovery
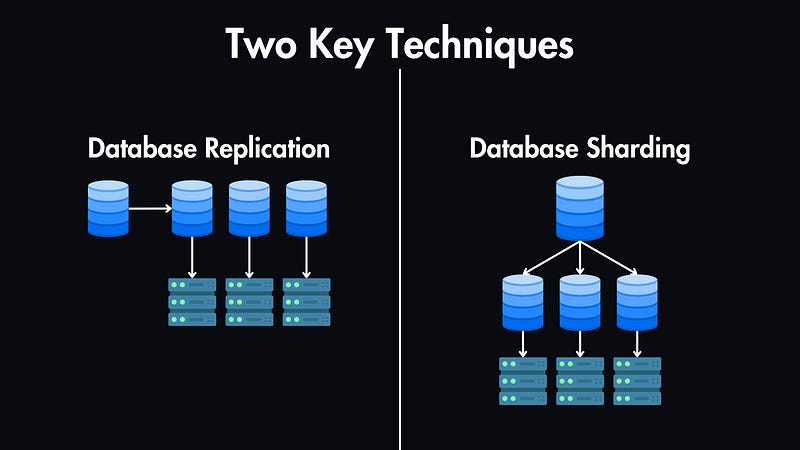
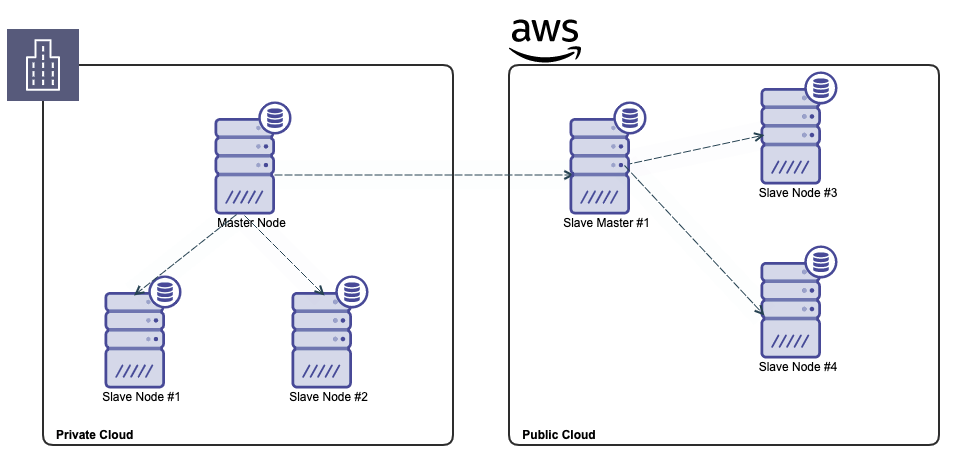
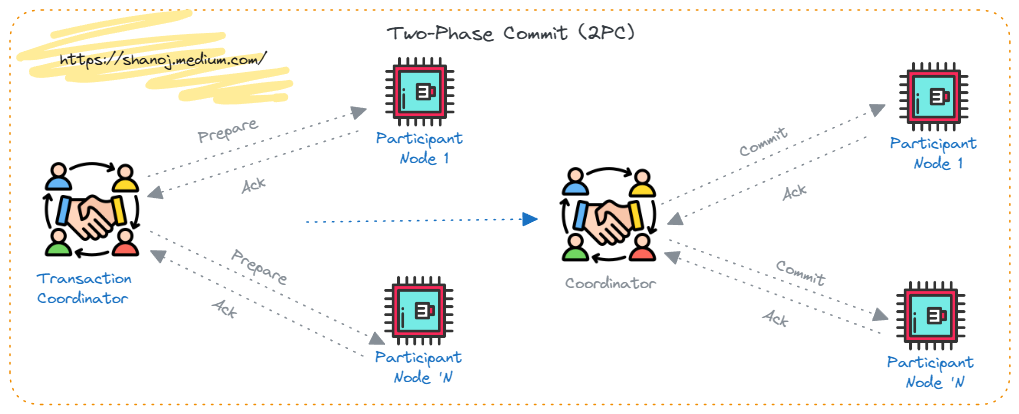
📊 13. Distributed Transactions
🔹 Challenges
- Network failures
- Data consistency across nodes
🔹 Two-Phase Commit (2PC)
- Prepare phase
- Commit phase
🔹 Three-Phase Commit (3PC)
Improved version of 2PC
🌐 14. Transactions in Modern Databases
🔹 SQL Databases
- Strong ACID compliance
🔹 NoSQL Databases
- Often use BASE model
- Basically Available
- Soft state
- Eventually consistent
⚖️ 15. ACID vs BASE
| Feature | ACID | BASE |
|---|---|---|
| Consistency | Strong | Eventual |
| Availability | Moderate | High |
| Use Case | Banking | Social media |
📈 16. Performance Considerations
- High isolation → slower performance
- Low isolation → faster but risky
🔹 Trade-offs
- Consistency vs performance
- Isolation vs concurrency
🧩 17. Real-World Applications
🔹 Banking Systems
- Money transfer
- Account updates
🔹 E-commerce
- Order processing
- Payment transactions
🔹 Airline Booking
- Seat reservation
🧠 18. Advanced Topics
- Nested transactions
- Long-running transactions
- Savepoints
- Distributed consensus
🏗️ 19. Best Practices
- Keep transactions short
- Avoid unnecessary locks
- Use proper isolation level
- Monitor performance
⚠️ 20. Common Issues
- Deadlocks
- Blocking
- Performance bottlenecks
- Data inconsistency
🔮 21. Future Trends
- Cloud-native transactions
- Distributed ACID systems
- New consistency models
🏁 Conclusion
Transactions and ACID properties form the core foundation of reliable database systems. They ensure that even in complex, concurrent, and failure-prone environments, data remains:
- Accurate
- Consistent
- Safe
- Durable
Mastering transactions is essential for building robust applications, especially in systems where correctness is critical.